Ce cours (préparé par Dr. Philippe MARTIN) introduit divers aspects importants de la
gestion de connaissances [knowledge management (KM)] :
0. La tâche de représentation des connaissances (RC) [knowledge representation (KR)]
s. Ses modèles structurels et sémantiques : modèles de données, ontologies de langage
p. La présentation des RCs : notations textuelles ou graphiques
o. Ses méthodologies et/ou ontologies de haut niveau
-1. Tâches précédant la RC
i. Information (données vs. connaissances), sémantique, objet formel
g. Tâches dites "de gestion de connaissances" et leurs supports (SGC, SGBC, SBC)
e. Élicitation/extraction de connaissances (auprès d'experts ou dans des documents)
+1. Tâches succédant/contrôlant la RC (-> exploitant des RCs)
s. Stockage et partage/distribution de RCs
e. Exploitation de RCs
Le CC du lundi 3/12/2018 16:15-18:15 aurait porté sur les parties que
nous avons vues en cours,
plus ce corrigé de CC de 2015
et ce corrigé de CC de 2016.
Introduction : quelques définitions et exemples
-1.i.0. Chose,
information (données vs. connaissances),
sémantique, objet formel
0.p.0. Exemples d'introduction pour les RCs et les requêtes
0.m.0. Règles de base pour la RC
0.p.0. Exemples de RCs
+1.e.0. Exemples de relations d'implication/généralisation/exclusion
-1.g. Tâches dites "de gestion de connaissances" et leurs supports (SGC, SGBC, SBC)
+1.s. Stockage et partage/distribution de RCs
+1.s.bc. Base de données/connaissances, ontologie, SGBC, SGBD
+1.s.web. Web 2.0/3.0/sémantique,
web de données/connaissances
0.s. Modèles structurels et sémantiques
0.s.web. W3C, standards et couches du Web sémantique
0.s.objet. Objet/symbole/phrase formel(le) ou non
0.s.quantif. Quantificateur, définition, phrase bien formée
0.s.mult. Multiplicité, cardinalité
0.s.langage. Noeud, langage de représentations de connaissances
0.s.semant. Objet/relation sémantique
0.s.formel. Commande, connaissance (semi-)formelle
0.s.contexte. Méta-phrases (contextes)
0.s.1erOrdre. Entité/type/phrase/logique/notation d'ordre 0, 1, 2..*, notation de haut niveau
0.s.BDD. Représentation d'une BC via une BDD; modèles de données
... suite du sommaire page suivante ...
Suite du sommaire :
+1.e. Exploitation de RCs
(partie non sujette à évaluation)
+1.e.types. Types d'inférences (+ décidabilité et complexités associées)
+1.e.comp. Comparaison et recherche de termes et de phrases
+1.e.fusion. Jointure/fusion de phrases
0.o. Méthodologies et/ou ontologies de haut niveau
0.o.0. Ontologies de language / ~haut niveau / domaine / ...
0.o.m.task.0. Méthodologie/tâches/modèles d'ingénierie des connaissances
0.o.m.task.1. Cycle de vie "logiciel" / "acquisition des connaissances"
0.o.m.task.2. Tâches génériques de résolution de problème
0.o.m.task.3. Exemple de modèle de tâche générique
0.o.m.task.4. Tâches et méthodes dans CommonKADS
0.o.m.task.5. Approches dirigées par les modèles / données
0.o.descr. Contenu/medium de description
0.o.tc. Types de concept de plus haut-niveau essentiels
0.o.tr. Types de relation essentiels
(les sections suivantes ne sont pas sujettes à évaluation)
0.o.meta. Méta-propriétés: (anti/semi-)rigidité, identité, unité, dépendence, rôle, mixin, résumé
0.o.part. Les relations "partie de"
Ne pas faire d'opérationalisation dans la phase de modélisation,
représenter/partager des informations
0.o.m.repr.1. ... d'une manière correcte et précise
0.o.m.repr.2. ... d'une manière organisée
0.o.m.repr.3. ... d'une manière organisée via des relations d'argumentation
0.o.m.repr.4. ... d'une manière explicite et sans perte
0.o.m.repr.5. ... et des techniques pour l'évaluation collaborative
0.o.m.repr.6. ... d'une manière modulaire au sein d'une BC centralisée/distribuée
0.o.m.repr.7. ... d'une manière modulaire à des fins de programmation
0.o.m.repr.8. ... d'une manière à la fois centralisée et distribuée
Annexes. Illustration du besoin (dans l'industrie) de personnes formées aux
technologies du Web Sémantique
A.1. Exemples d'offres d'emplois liées au Web Sémantique
A.2. Autres documents/livres intéressants
A.3. Quelques ontologies et outils bien connus - sujets d'exposés
E.g.
(latin: exempli gratia): "par exemple".
I.e. (latin: id est):
"c'est-à-dire".
Vs.: "versus".
/: "ou". // : "ou bien".
|: (quasi-)"alias" (entre 2 termes, dans le contexte où
ils sont définis).
Chose [thing]: tout ce à quoi quelqu'un peut penser est une chose.
Une partition possible des choses est celle distinguant
- les situations (processus, états, événements), et
- les entités (ce qui n'est pas une situation, e.g.,
un objet physique, un objet d'information,
un attribut, un concept, etc.).
Objet (d'information) [(informational) object,
resource]: référence
à une chose ("ressource Web" si c'est une chose référable par un
URI), donc
- soit un symbole (référence qui n'est pas une description), e.g.,
un terme qui est le (e.g., la chaîne de caractères "bird"),
un élément graphique (e.g., un icône, une flèche,
la séparation entre 2 colonnes d'une table),
un son particulier, ... );
- soit une phrase
[(declarative) sentence or
(logic) statement,
not proposition]: une
combinaison de symboles décrivant une chose; en d'autres termes, une
description
non encore affirmée/pensée/crue et donc ni vraie ni fausse.
Une phrase peut d'ailleurs
être un paramètre d'un opérateur de recherche.
À part les quantificateurs (exists, forall, ...),
tout objet a une source associée,
e.g., son (groupe de) créateur(s), son interprète
ou le fichier qui contient la déclaration/définition de l'objet.
Dans les exemples des deux pages suivantes, ces sources ne sont pas
précisées (i.e., elles sont implicites).
Objet formel: objet (d'information) déclaré par sa source comme ayant un sens unique.
Information: donnée ou bien (représentation de) connaissance (RC)
(mais la sémantique d'une RC peut ne pas être prise en compte et donc
une RC peut être recherchée/traitée comme si elle
n'était qu'une donnée).
Donnée [data]: symbole, ou
ensemble de symboles, qui n'est pas un objet sémantique,
e.g., les informations d'un document écrit
en langage naturel ou les informations d'une base de données.
Méta-donnée:
information sur une autre information, i.e., associant une donnée ou
une connaissance à une information pour en exprimer une partie du sens.
(Représentation de) connaissance (RC) [knowledge (representation)]:
objet sémantique qui est une phrase bien formée.
Cela sous-entend que les symboles sont reliés par des relations
sémantiques et que la manière de les relier a un sens dans une logique,
e.g., la logique du 1er ordre.
Représenter des connaissances: créer des (représentations de)
connaissances.
Une sémantique: un sens (une signification).
En: A motel is an hotel. A king-size bed is a bed.
Bates Motel has 2 bedrooms with a king-size bed, at 40$/night. //in 2018
FE: Bates_motel has for type Motel which is subtype of Hotel ;
King-size_bed is subtype of Bed ;
Bates_motel has for part 2 Bedroom which have for part a King-size_bed
and which have for price-per-night 40 Dollar ;
FLnc: //"nc": "no context" (and here: "not connected")
Bates_motel type: ( Motel supertype: Hotel ) ; King-size_bed subtype of: Bed ;
Bates_motel part: ( 2 Bedroom price-per-night: 40 Dollar,
part: a King-size_bed ) ;
FLc: //"c": "with context" (and here: "connected")
Bates_motel type _[. -> .]: ( Motel supertype _[. -> .]: Hotel ),
part _[. -> 2 ?b] : ( Bedroom part _[?b -> a]: (King-size_bed supertype _[. -> .]: Bed),
price-per-night _[?b -> 40]: Dollar ) ;
FL-DF: //"DF": "display form", i.e. "graphique" ("2D") hence connected, no parenthesis, hardly parsable
Bates_motel --type _[. -> .]--> Motel --supertype _[. -> .]--> Hotel
|---part _[. -> 2 ?b]--> Bedroom --part _[?b -> a]--> King-size_bed --type _[any -> .]--> Bed
|---price-per-night _[?b -> 40]--> Dollar
Q1: //"query 1": get the part of the knowledge base (KB) which includes and relates all the
// graphs that imply the one given in parameter of the search operator "?"
? [ a Bedroom price-per-night: at most 50 Dollar ]
Q2: //get the list of all graphs that imply the parameter ("list": no relations between the graphs)
?s [ a Bedroom price-per-night: at most 50 Dollar ] <= ?s
Q3: //get the list of all graphs that specialize the parameter
?s [ a Bedroom price-per-night: at most 50 Dollar ] =< ?s
Q4: //get the list of all graphs that the parameter implies
?s [ a Bedroom price-per-night: at most 50 Dollar ] => ?s
Q5: //get the list of all graphs that the parameter specializes
?s [ a Bedroom price-per-night: at most 50 Dollar ] >= ?s
Examples of specializations are in section +1.0.e
Queries are further presented in section +1.e.comp
"Structured discussions"
- un des Google Docs de 2017
- old examples (do not imitate)
- 1er Google Doc de 2018
Règles à suivre dans tous vos exercices de modélisation
(à faire par les M2 info avant leur CC :
* apprendre ces règles et comprendre les exemples des pages suivantes,
et donc
- savoir lire tous les exemples des pages suivantes d'après ces
règles,
- savoir répondre aux questions de ce CC1
sans regarder la solution ;
* faire les exercices de la page suivante et de la page 12).
1. Une relation binaire de type ?rt (e.g., 'subtype' or 'part')
depuis un nœud source ?s (e.g., 'feline' or 'at least 80% of car')
vers une destination ?d (e.g., 'cat' or 'at most 100 wheel')
se lit :
" ?s has/have for ?rt ?d ".
E.g. :
`feline > cat´ ou [feline > cat]
ou `feline subtype: cat´ se lit
"feline has for subtype cat" (ou "the type feline has for subtype the type
cat"),
[at least 80% of car part: at most 100 wheel] se lit
`at least 80% of car have for part at most 100 wheel´.
Ce dernier exemple peut aussi se lire :
"at least 80% of instances of the
type car have for part
at most 100 instances of the type wheel". Enfin,
conformément à la règle 7 ci-dessous,
`car part: at most 100 wheel´ se lit
"any (instance of) car has for part at most 100 (instance of)
wheel(s)".
2. Si ?rt est suivi de "of" (pour inverser la direction de la relation),
il vaut mieux lire
" ?s is/are ?r of ?d ".
E.g., `cat < feline´ (i.e., `cat subtype of: feline´)
se lit
"cat is subtype of feline" et
`at least 51% of wheel part of: a car´ se lit
"at least 51% of wheels are part of a car".
3. `?st subtype of: ?t´ (alias, `?st < ?t´) est équivalent
à `any ?st instance of: ?t´,
i.e., ` `?i type: ?st´ => `?i type: ?t´ ´.
Formellement :
[?st subtype of: ?t] <=> [ [?i instance of: ?st] => [?i instance of: ?t] ].
Informellement :
"?st est sous-type de ?t ssi toute instance de ?st est aussi
instance de ?t".
4. `?t > excl{?st1 ?st2}´ <=> `?t > ?st1 (?st2 exclusion: ?st1)´
(informellement :
?st1 et ?st2 sont sous-types de ?t et ne peuvent avoir ni sous-type commun,
ni instance commune).
5. Si le nœud destination d'une relation est source/destination d'autres
relations,
il faut isoler ce nœud destination et ses autres
relations avec des parenthèses
(comme dans l'exemple du
paragraphe précédent) pour que l'interpréteur du
langage puisse savoir que ces autres relations sont sur le nœud
destination,
pas sur le nœud source.
Similairement, dans une notation textuelle, lorsque 2 relations de même
source
se suivent, il faut les séparer par un symbôle.
En FL, c'est la virgule (cf.
exemples).
À l'oral ou en Formalized-English (FE : FL lu avec les règles de
lecture), les mots "that"/"which" et "and" peuvent être
utilisés comme dans
l'exemple suivant :
En: any white cat is on a blue mat and is happy.
FL: any ^(cat color: a white) place: (a mat color: a blue),
experiencer of: an happiness;
FE: any `cat that has for color a white´
has for place a mat that has for color a blue , and
is experiencer of an happiness. //", and" ou ", ," ou "and and" car
// il faut remonter 2 relations (color et place) pour trouver le bon
// nœud source. À l'oral, il vaut mieux dire "and and".
//Dans le cas simple ci-dessus, les quotes pourraient être omises
// mais il vaut mieux les garder à l'écrit. À l'oral, il vaut
// mieux marquer une pause avant et après chaque quote.
6. Les noms utilisés dans les nœuds relation/source/destination doivent
être des
noms communs/propres (jamais d'adjectif, verbe, ...)
au singulier et en
minuscules (sauf pour les noms propres s'ils
prennent normalement des majuscules).
7. Les relations qui ne sont pas entre types et/ou des individus nommés
(i.e., pas les relations sous-type/instance mais la
majorité des relations)
doivent préciser comment les
nœuds source et destination
sont quantifiés
Exemples de quantificateurs : "a" (i.e., "there exists a"),
"any" (i.e., "by definition, each"),
"every" ("by observation, each"), "most" (i.e., "at least 51%"), "at most 20%",
"0..20%", "at most 20", "0..20", "between 2 and 3", "2..3".
Toutefois, si le quantificateur du nœud source est
'any' - i.e., s'il s'agit d'une définition -
celui-ci peut être omis : c'est le quantificateur par
défaut pour un nœud source.
Pour le nœud destination, 0..* est le quantificateur par défaut.
Donc :
[car part _[any->0..*, 0..*<-any]: wheel]
=> ( [any car part: 0..* wheel] <=>
[car part: 0..* wheel] )
Lorsque c'est possible, il vaut mieux rendre les quantificateurs
explicites.
C'est toujours possible pour des RCs isolées
ou en mettant les quantificateurs
dans les contextes
associées aux nœuds relations au lieu de les mettre dans
leurs nœuds sources/destinations.
8. Si vous hésitez entre 2 relations dont une seule est transitive,
choisissez la transitive
(e.g., choisissez "<=" au lieu de
"argument").
Sinon, si vous hésitez entre 2 relations, choisissez la plus
basique|générique (et
utilisez des nœuds
concept adéquats pour ne pas perdre en précision).
Différentes phrases représentant la même chose :
En: Every green mouse is (agent of a) dancing. //"every" -> this is an observation, hence at least one green_mouse exists // -> instead of: ∀?m green-mouse(?m) => ( ∃?d dancing(?d) ∧ agent(?d,?m) ) // the simpler following representation in LP can be given LP: ∀?m ∃?d green-mouse(?m) ∧ dancing(?d) ∧ agent(?d,?m) FL-DF: every green_mouse --agent of--> a dancing //only if "every" has priority over "a" FL-DF: green_mouse --agent of _[every->a]--> dancing FLc: green_mouse agent of _[every->a]: dancing; FLc: green_mouse agent of: dancing __[every->a]; FLnc: every green_mouse agent of: a dancing //all the above FL-DF and FL phrases should be read in the same way: // every green mouse is agent of a dancing
Les phrases ci-dessous sont syntaxiquement correctes mais
ne représentent pas la même chose que ci-dessus.
En: There is a dancing to which every green_mouse participate. En: There is a dancing that has for agent every green_mouse. LP: ∃?d ∀?m dancing(?d) ∧ green-mouse(?m) ∧ agent(?d,?m) FL-DF: dancing --agent _[a->every]--> green_mouse FL-DF: green_mouse <--agent _[every<-a]-- dancing FLnc: a dancing agent: every green_mouse //these last 5 FL-DF and FL phrases can/should be read in the same way: // (there is) a dancing that has for agent every green_mouse En: every mouse is dancing and is green LP: ∀?m ∃?g ∃?d mouse(?m) ∧ dancing(?d) ∧ green(?g) ∧ agent(?d,?m) ∧ color(?m,?g) FL-DF: mouse --agent of _[every->a]--> dancing //graph unconnected to the next one: mouse --color _[every->a]--> green FL-DF: dancing <--agent of _[a<-every]-- mouse --color _[every->a]--> green FL-DF: dancing <--agent of _[a<-every ?m1]-- mouse --color _[every ?m2->a]--> green FL-DF: dancing <--agent of _[a<-every ?m]-- mouse --color _[every ?m->a]--> green FLnc: every mouse agent of: a dancing, color: a green //these last 5 FL-DF and FL phrases should be read in the same way: // every mouse is agent of a dancing and has for color a green En: every mouse that dances is green LP: ∀?m ( (mouse(?m) ∧ ∃?d dancing(?d) ∧ agent(?d,?m)) => (∃?g green(?g) ∧ color(?m,?g)) ) //LP: ∀?m ( dancing_mouse(?m) ∧ (∃?g green(?g) ∧ color(?m,?g)) ) FL-DF: dancing_mouse --type _[any ?dm ^-> .]--> mouse | |---agent of _[?dm ^-> a]--> dancing //^dm -> dancing_mouse |---color _[every -> a]--> green FL-DF: mouse --agent of _[any ^dm ^-> a]--> dancing //^dm -> dancing_mouse |---color _[every ^dm -> a]--> green //every ^dm is green FLnc: every ^(mouse agent of: a dancing) color: a green //these last 3 FL-DF and FL phrases can be read in the same way: // every mouse that is agent of a dancing has for color a green //the FL-DF phrases can also be read: // every dancing_mouse -- defined as a mouse that is agent of a dancing -- // has for color a green
Différentes phrases représentant la même chose :
En: The cat Tom and at least 2 mice are dancing together. Every green mouse is (constantly) dancing. LP: //with "at least 1 mouse": ∃?d ∃?m dancing(?d) ∧ mouse(?m) ∧ cat(Tom) ∧ agent(?d,Tom) ∧ agent(?d,?m) ∀?m ∃?d green-mouse(?m) ∧ dancing(?d) ∧ agent(?d,?m) FL-DF: dancing <--agent of _[. -> a ?d]-- Tom <--instance-- cat |---agent _[?d -> 2..*]--> mouse |---agent _[a <- every]--> green_mouse --type _[any ?gm ^-> .]--> mouse |---color _[?gm ^-> a]--> green FL-DF: dancing --agent _[a ?d <- 1]--> Tom <--instance-- cat |---agent _[?d <- 2..*]--> mouse |---agent _[a <- every ^gm]--> mouse --color _[any ^gm ^-> a]--> green FL-DF: dancing --agent _[a ?d <- .]--> the cat Tom |---agent _[?d <- 2..*] _[a <- every ^gm]--> mouse --color _[any ^gm ^-> a]--> green FL-DF: 2..* mouse <--agent-- a dancing --agent--> the cat Tom green <--color _[a <-^ any ^gm]-- mouse --agent _[every ^gm -> a]--> dancing FLc: dancing agent _[a ?d <- .]: (Tom instance of: cat), agent _[?d -> 2..*]: mouse, //or: _[?d <- 2..*] agent _[a <- every]: (green_mouse = ^(mouse color: a green)); FLc: dancing agent: the cat Tom __[a ?d <- .], agent: mouse __[?d<-2..*], agent: ^(mouse color: a green) __[a <- every]; FLnc: the cat Tom agent of: (a dancing agent: 2..* mouse); every ^(mouse color: a green) agent of: a dancing;
Ci-après, 3 exemples de "phrases affirmées" équivalentes, en
En [English], en LP (logique des prédicats en notation de Peano) et
dans les LRCs
CGLF (Conceptual Graph Linear Form), FE (Formalized English),
FCG (Frame/For Conceptual Graph), FL (For Links),
N3 (Notation 3),
KIF (Knowledge Interchange Format) et R+O/X (RDF+OWL linéarisé avec XML).
Ces exemples permettent d'illustrer et d'expliquer oralement l'usage de
quantificateurs et de définitions,
ainsi que plusieurs notions liées aux "relations sémantiques
(entre "noeuds conceptuels/sémantiques").
La notion de "relation sémantique" est précisée plus tard.
Si vous souhaitez d'autres exemples, cliquez ici.
Les parties en italique sont optionelles (elles ne sont utilisées que pour la lisibilité).
Également pour une question de lisibilité, les sources des termes et des
phrases ne sont pas précisées
sauf pour le terme pm#blue_man et les termes venant de OWL ou de RDF.
1) En : Tom -- who is a man -- owns a red hat and a bird. LP : ∃?h hat(?h) ∧ ∃?r red(?r) ∧ ∃?b bird(?b) ∧ man(Tom) ∧ owner(?h,Tom) ∧ color(?h,?r) ∧ owner(?b,Tom). CGLF: [man: Tom]- { <-(owner: *)<-[hat: *]->(color)->[red: *]; <-(owner)<-[bird] }. FCG: [the man Tom, owner of: (a hat, color: a red), is owner of: a bird]; FCG: [Tom, type: man, owner of: (a hat, color: a red) (at least 1 bird)]; FE : The man Tom is owner of a hat with color a red, and is owner of a bird. FE : The man Tom is owner of a hat that has for color a red, and is owner of a bird. FLnc: Tom type: man, owner of: a ^(hat color: a red) a bird; N3 : [a hat; color [a red]] owner [Tom a man; owner_of [a bird]]. N3 : a hat; color [a red]; owner [Tom a man; owner_of [a bird]]. N3 : [:h rdf:type hat] color [a red]; owner [Tom a man; owner_of [a bird]]. KIF: (exists ((?h hat)(?r red)(?b bird)) (and (type Tom man) (owner ?h Tom) (color ?h ?r) (owner ?b Tom))) R+O/X: <hat> <color><red/></color> <owner> <man rdf:ID="Tom"><owner_of><bird/></owner_of> </man> </owner> </hat> <owl:ObjectProperty rdf:ID="owner_of"><owl:inverseOf rdf:resource="owner"/> </owl:ObjectProperty>
2) En : (It appears that) all birds fly in the same sky. //-> observation/belief (can be false) LP : ∃?s ∀?b ∃?f sky(?s) ∧ bird(?b) ∧ flight(?f) ∧ agent(?f,?b) ∧ place(?b,?s) CGLF: [proposition: [sky:*s] [proposition: [sky:*s]<-(place)<-[bird: @forall]<-(agent)<-[flight] ] ]. FCG: [a sky, place of: every ^(bird, agent of: a flight)]; FE : There is a sky that is place of every `bird that is agent of a flight´. FLnc: a sky place of: every ^(bird agent of: a flight); N3 : @forSome :s . @forAll :b . { [:s a sky] [:b a bird] } => {:b agent of a flight}. KIF: (exists ((?s sky)) (forall ((?b bird)) (exists ((?f flight)) (and (agent ?f ?b) (place ?b ?s))))) 3) En : By definition of the term "bird" by pm, birds fly. //definition -> cannot be false CGLF: pm#bird (*x) :=> [pm#bird: *x]<-(agent)<-[flight]. FCG: [any pm#bird, agent of: a flight]; FE : any pm#bird is agent of a flight. FLc : pm#bird agent of _[any->1..*]: flight; FLc : pm#bird agent of: flight __[any->1..*]; FLnc: pm#bird agent of: 1..* flight; N3 : pm:bird rdfs:subClassOf [a owl:restriction; agent of a flight]. //note: owl#restriction does not have a normal semantics: it is // an anonymous type when used as destination of a relation // between types (e.g., rdfs:subClassOf or owl#equal) // and otherwise it refers to "any" instance of this type KIF: (defconcept pm#bird (?b) :=> (exists ((?f flight)) (agent ?f ?b))) R+O/X: <owl:Class rdf:about="±bird"> <rdfs:subClassOf> <owl:restriction><agent_of><flight/></agent_of> </owl:restriction> </rdfs:subClassOf> </owl:Class> <owl:ObjectProperty rdf:ID="agent_of"><owl:inverseOf rdf:resource="agent"/> </owl:ObjectProperty>
Voici, en FL et en FL-DF ("DF": "Display Form"), l'union des 3 exemples précédents en supposant que dans les 2 premiers exemples "bird" réfère à pm#bird :
En: Tom -- a man -- owns a red hat and a pm#bird. (It appears that) all pm#bird fly in the same sky. By definition of the term "bird" by pm, birds fly. FL: Tom instance of: man, //in this page, "intance of" is used instead of "type" owner of: (a hat color: a red), owner of: a (pm#bird place: sky __[every<-a], agent of: a flight //implicitly: _[any->a] ); FL-DF: man --instance--> Tom <--owner-- a hat --color--> a red ^ a pm#bird --owner--| ^ |--instance-- pm#bird --place _[every<-a]--> sky |--agent _[any->a]--> flight FL-DF: /-> the man Tom <--owner-- a hat --color--> a red /--owner _[.<-a]-- pm#bird --place _[every<-a]--> sky |--agent _[any->a]--> flight
`no Animal can be agent of a Process´
# #
`at least 1 Bird ⇐ `at least 50% of Bird
can be agent of can be agent of
a Flight´ a Flight´
⇑ ⇖ ⇖
`1 Bird `Tweety can be `every Bird
can be agent of a Flight can be
agent of that has for duration agent of
a Flight´ at least 0.5 Hour´ a Flight´
⇑
`Tweety is agent of a Flight that
has for duration at least 0.5 Hour´
Legend. #: exclusion; ⇒: implication; every sentence is in FE;
relation types are in italics; concept types begin by an uppercase;
the authors of terms, sentences and relations are not represented;
in FE, "every" and "%" are for "observations" and imply "at least 1",
whereas "any" is for "definitions" and does not imply "at least 1";
the distinction is important since observations can be false
while definitions cannot (← agents can give any identifier they want
to the types they create) and thus cannot be corrected or contradicted
`a Lodging with place La_Réunion´
⇗ ⇖
`a Double_room Hotel_room `an Hotel_room
with part 2 Bed, with part at least 2 Bed,
with place the Hotel_Mercure with part Free Wifi,
that has for name "Créolia" and with name a Regular_expression "*a",
that has for place with place
Sainte-Clotilde, and Saint-Denis_de_La_Réunion and
with cost 69$ per Night´ with cost at most 100$ per Night´
Legend: same as in the previous page.
Connaissance tacite: connaissance qui n'est pas explicite, i.e., qui n'a pas été décrite précisément dans un document ou un SGBC. Certaines connaissances, comme les savoir-faire et la reconnaissance de situations ou d'objets (visages, écriture, ...), sont difficiles à décrire ou définir précisément et donc à représenter. En psychologie cognitive, cette distinction se retrouve dans la distintion entre mémoire procédurale et mémoire déclarative.
"Gestion des connaissances" (au sens des industriels)
[knowledge management]:
ensemble des techniques permettant de collecter/extraire, analyser, organiser
et partager des informations, le plus souvent à l'intérieur
d'une organisation, e.g., les connaissances importantes d'un employé
(carnet d'adresses, trucs/expertise, etc.)
avant qu'il ne parte à la retraite.
Ces informations sont généralement stockées sous la forme de
documents informels, très rarement via des représentations de
connaissances, du moins jusqu'à présent.
Un outil permettant une telle gestion est un
système de gestion de connaissances (SGC)
[knowledge management system (KMS)].
"Gestion|ingénierie des connaissances" (au sens des universitaires)
[knowledge engineering]:
ensemble des techniques permettant de collecter/extraire, représenter, organiser et
de partager des représentations de connaissances.
Un système de gestion de BC (SGBC) [KB management system (KBMS)] est un
des outils permettant une telle gestion. D'autres outils sont ceux de
collection/extraction et analyse de connaissances qui aident à créer
un SGBC.
Système à base de connaissances (SBC): tout outil exploitant des représentations de connaissances par exemple pour résoudre certains problèmes. Techniquement, un SGBC est aussi un SBC mais est rarement classé en tant que tel. Les systèmes experts sont des SBCs mais ne sont pas forcément basés sur des "connaissances profondes" (représentations détaillées de connaissances nécessaires à un raisonnement).
Gestion de contenu
[Enterprise Content Management (ECM)] : prendre en compte sous
forme électronique des informations qui ne sont pas structurées, comme les
documents électroniques, par opposition à celles déjà
structurées dans les SGBD. Ceci peut
être vu comme un cas particulier de "gestion des connaissances,
au sens des industriels".
De plus, si des métadonnées "précises"
sont utilisées pour indexer les documents,
"gestion de contenu" implique aussi des tâches d'ingénierie des connaissances".
Le terme "contenu" a donc divers sens contradictoires. Dans "gestion de contenu", ce terme réfère à des données non structurées. Dans "recherche de documents/informations par le contenu", il réfère à la sémantique des informations, par opposition à leur structure ou leurs aspects lexicaux (orthographe, ...). Dans "recherche d'images par le contenu", il réfère soit à la sémantique de l'image (les choses qu'elle contient et leur relations spatiales), soit à des caractéristiques visuelles de l'image comme les textures, couleurs et formes qu'elle contient.
Question de contrôle (après réponse aux questions
éventuelles des étudiants):
- représentez graphiquement et en FL les relations de sous-typage et d'exclusion
entre SBC, SGC, SE, SGBC et SGBD,
- représentez graphiquement et en FL les relations de sous-typage et/ou de
sous-tâche
entre "gestion de contenu",
"gestion de connaissances, au sens des industriels" (GCI) et
"gestion des connaissances, au sens des universitaires" (GCU)
(note: une relation de sous-tâche ne peut pas directement lier deux
types de tâches,
elle ne peut lier que des instances de tâches -> utilisez des
multiplicités).
//solution en FL:
SGC > excl{ SGBD (SBC > SE SGBC) };
process
> (GCI //Gestion/ingénierie des Connaissances au sens des Industriels
> excl{ GCI_sur_donnees //ce que la plupart des industriels font
(GCI_sur_connaissances
> (GCU //... au sens des universitaires
subtask: GCI __[any->0..*, 0..*<-any] //rare mais possible
))
},
subtask: gestion_de_contenu __[any->0..*, 0..*<-any]
GCU __[any->0..*, 0..*<-any] //e.g., pour certaines meta-data en GCI
)
(gestion_de_contenu subtask: GCI __[any->0..*, 0..*<-any]);
//note: la multiplicité/cardinalité "any->0..*" (ou 0..*<-any) peut être omise
Répertoire d'information [information repository]: base de données ou base de connaissances.
Base de données (BD)
[database (DB)]:
collection structurellement organisée de
données.
En effet, dans une BD, il n'existe essentiellement que trois 'types de relations'
explicites : partie(-de), type(-de), attribut(-de).
Un document structuré (par exemple, un document XML) peut être
considéré comme une BD. Inversement, une BD peut être
stockée dans un document structuré.
Les types de données autorisées - et leurs inter-relations possibles -
sont souvent énumérés dans un "schéma de BD".
Ce schéma est fixe (prédéfini): l'utilisateur de la BD ne peut pas
ajouter dynamiquement (i.e., déclarer ou définir) de nouveaux types
de données et ne peut pas définir de nouveaux types de relations.
Un document XML peut être plus souple qu'une BD relationnelle: il
est aussi souple
qu'une BD orientée objet dans la représentation
de certaines hiérarchies (e.g., celles structurées par
des relations partie-de) et peut aussi ne pas avoir de schéma associé
(auquel cas il peut stocker
n'importe quoi mais aucun contrôle n'est alors
effectué).
Une BC peut stocker n'importe quel type de contenu et néanmoins permettre
de nombreux
contrôles car les relations et les objets qu'elles relient
ont des contraintes|définitions associées
exploitables pour effectuer des inférences logiques.
SGBD [DBMS]:
système de gestion de BD [DB management system].
Certains SGBDs - e.g., les NoSQL - ne semblent pas
avoir de schéma : ils ne gèrent que des tableaux
associatifs (donc plusieurs tables|objets possibles mais seulement 2 colonnes
par table :
"nom d'attribut de l'objet" - "valeur pour cet attribut").
Il est possible de dire qu'ils n'ont pas
de schéma mais, techniquement ou
virtuellement, ils ont en fait un schéma fixe très
général (chaque table doit avoir les deux colonnes mentionnées
ci-dessus) que même le
concepteur de la BD ne peut changer.
Base de connaissances (BC)
[(machine readable) knowledge base (KB)]:
collection de représentations de connaissance (RCs).
L'utilisateur d'une BC peut y ajouter dynamiquement de nouveaux types d'objets
(via des définitions ou déclarations) et les utiliser.
Une BC est composée d'une ontologie et, généralement, d'une base de
faits exprimée grâce aux termes définis dans l'ontologie.
SGBC [KBMS]: système de gestion de BC [KB management system].
Base de faits: ensemble de croyances.
Ontologie: ensemble de termes formels avec, associés à ceux-ci et portant sur eux, des définitions partielles/totales et des croyances.
Onto-terminologie: ensemble de termes formels ou informels connectés entre eux par des relations sémantiques ou lexicales.
Thésaurus: ensemble de termes informels liés par des relations sémantiques ou lexicales.
Exercice (avec début de solution donné et expliqué) :
- représentez en FL-DF puis en FL les relations de sous-typage, d'exclusion
et de sous-partie /* et de "outil support" (pm#supporting_tool) */ entre les termes en gras
de la page précédente.
//solution étendue en FL-DF:
entity
/ \
/> \>
/ \
v v
tool--exclusion-->information_repository
/ \ | \
/> \> |> \>
v v v v
DBMS KBMS --[0..*]--p--[0..*]-->KB DB<--[0..*]--p--[0..*]--DBMS
| /| |\___
| / | \ \________________
|> p/ p p \p /*part*/
| / | \ \
| [0.1]/ [1] \[0..1] \[0..1]
v v v v v
WebKB fact_base ontology onto-terminology thesaurus
| ↑ / \[0..*] ↑[0..1]
|instance \-[1]--p---/ \---p--/
v
WebKB_on_the_12/11/2010
//Notes: 1) For relations from a type or to a named instance
// the default multiplicities are [any->0..*] and [0..* <-any]
// (hence, [0..* <-any] is sometimes ommited above).
// 'any->' and '<-any' can be (and are) also ommited.
// 'most->' or '<-54%' would need to be explicitly mentionned.
// 2) Compared to the solution in FL below, the above solution in FL-DF
// does not represent some relations from the parts of 'KB' :
// - their 'subtype of' relations to 'information_repository'
// - the exclusion relations between them
entity
> excl //the next subtypes (tool and information_repository) are exclusive
{ (tool > (DBMS part: DB __[any->0..*, 0..*<-any])
(KBMS part: KB __[any->0..*, 0..*<-any],
exclusion: DBMS,
> (WebKB instance: WebKB_on_the_12/11/2010)
)
)
(information_repository
> excl //the next subtypes are exclusive
{ (KB part: fact_base __[any->0..1, 0..*<-any] //any KB has for
ontology __[any->1, 0..*<-any] // part only 1
onto-terminology __[any->0..1, 0..*<-any] // ontology,
thesaurus __[any->0..1, 0..*<-any],
> ontology //an ontology is a KB that has for part only 1 ontology
)
DB
base_of_fact
thesaurus
(onto-terminology part: ontology __[any->1, 0..*<-any]
thesaurus __[any->0..1, 0..*<-any]
)
}
)
};
WWW (Web)
[World Wide Web]: (système
hypermédia sur l')ensemble des
ressources (documents ou élément de documents,
bases de données/connaissances, ...) accessibles via internet.
À l'origine, techniquement, le Web n'est que l'implémentation
d'un système hypertexte très simple (HTTP + HTML + navigateur Web) sur
Internet (i.e., via
TCP et
DNS).
Web 2.0: mot "fourre-tout"
(utilisé à partir de 2001 mais enfin passé de mode) désignant
- les technologies liées à la construction de
pages Web dynamiques
(i.e., générables),
e.g., le
DOM (Document Object Model) et
Ajax (Asynchronous Javascript
and XML), et
- la participation des internautes à la construction et indexation de
documents Web via des
sites/systèmes collaboratifs tels que les wikis, les blogs, les
réseaux sociaux, les folksonomies
et les systèmes de
sciences citoyennes.
Par opposition à la partie du Web 2.0 du Web, le reste est un
"Web de documents statiques (i.e., non dynamiques)".
Web 3.0: mot "fourre-tout"
(utilisé à partir de 2009) désignant les futures applications,
combinaisons et évolutions des technologies récentes et en particulier
celles liées
- au Web Sémantique,
- à la mobilité, l'universalité et l'accessibilité:
internet des objets,
indépendance vis à vis des
supports matériels et des
systèmes d'exploitation, ...
- au graphisme vectoriel (e.g., SVG qui est en fait maintenant une ancienne
technologie) et
aux formulaires XForms.
"Web sémantique" [Semantic Web]: mot (surtout utilisé à partir de 1996, soit 4 ans après la naissance officielle du Web) désignant
Par opposition à la partie Web sémantique du Web, le reste est un "Web peu/non compréhensible par les machines".
Définitions plus précises (et équivalentes entre elles)
pour le 1er sens de "Web Sémantique" :
- sous-ensemble des informations du Web dont le sens a été au moins
partiellement défini dans
des formats standards (et donc que des logiciels peuvent utiliser pour faire
certaines déductions logiques pour de la
résolution de problèmes ou être plus (inter-)opérables).
- connaissances du Web exprimées dans des langages standards et
informations indexées par ces connaissances ou méta-données.
Règles élémentaires du Web des données [(Linked) Data Web]:
- identifier et relier le plus possible de choses en utilisant des
adresses URI HTTP,
- fournir à ces adresses des informations lisibles par les humains et par
les machines
(en utilisant des langages formels intuitifs ou bien en fournissant
différentes
versions écrites avec des différents langages; e.g., via le
mécanisme de
redirection HTTP code 302 et la variable User-Agent contenu dans les
entêtes des
requêtes HTTP, un serveur peut afficher une page en RDF/XML pour une
machine ou
une page HTML pour le navigateur d'une personne).
Exercice de contrôle (après réponse aux questions
éventuelles des étudiants):
- représenter graphiquement, en utilisant des patatoides puis un graphe,
les intersections entre les différents webs présentés jusqu'à présent
- après l'ajout de relations sous-type et exclusion au graphe par l'enseignant,
concevoir une représentation linéaire (alias, textuelle) de ce graphe.
La solution pour le graphe est à la page suivante.
Ci-dessous, une représentation/modélisation/solution possible, dans la notation FL,
pour le graphe demandé dans l'exercice précédent.
La page suivante propose une représentation graphique des 9 premières lignes ci-dessous.
Note: ici, "web" ou "WWW" réfère seulement à un ensemble de "descriptions"
ou de
"containeurs de descriptions" (fichiers, base de données, ...),
et non pas aussi aux techniques/applications qui exploitent cet
ensemble.
web
instance of: first_order_type, //optional (see Note 2 below)
subtype:
(static_web instance: static_WWW)
(web_2.0 //juste pour l'exemple car
instance: WWW_2.0, // introduire/représenter
exclusion: static_web // les types web_2.0, web_3.0, ...
) // semblent peu intéressants
(semantic_web
subtype: (knowledge_web instance: Knowledge_WWW)
(data_web instance: Data_WWW,
exclusion: knowledge_web),
//no exclusion with web_2.0 and web_statique since one can imagine
// an instance of semantic_web that is also static or web_2.0
instance: Semantic_WWW,
part: knowledge_web __[any->a]
data_web __[some->a]
),
instance: WWW_3.0 WWW_2.0_and_3.0 //not yet already declared above
(WWW
part: (WWW_2.0
part: WWW_2.0_and_3.0)
(WWW_3.0
part: WWW_2.0_and_3.0
(Semantic_WWW
part: (Data_WWW
part: Knowledge_WWW)
))
);
/* Note 1: ">" can be used instead of "subtype:".
Note 2: we could assume that, by default, a category that has subtypes is
a first-order type, unless it has instance which (by the same rule)
is a type; not all languages or inference engines assume that.
Note 3: the above representation assume that, by default, all
categories (types or individuals) with different names
are different; since this is not the case for most semantic web
languages and inference engines, we could add the 3 following lines.
*/
{WWW WWW_2.0 WWW_3.0 WWW_2.0_and_3.0
Semantic_WWW Data_WWW Knowledge_WWW} _[collective_set];
{semantic_web web_2.0 web_statique} _[collective_set];
//To represent that "no instance of 'semantic_web' can share a part with an
// instance of 'static_web'", i.e., that "no semantic web has for (proper) part
// something which is a (proper) part of a static_web", here are three
// equivalent ways in FL:
semantic_web
not part: (thing part: static_web __[?x->a]
) __[any->?x];
any semantic_web not part: (a thing part: a static_web);
no semantic_web part: (a thing part: a static_web);
Représentation graphique - dans la notation FL-DF (FL Display Form) -
des 9 premières lignes du code FL de la page précédente.
Les représentations graphiques prennent beaucoup de place et ne sont pas automatiquement interprétables.
FL-DF ne sera donc utilisée dans ce cours que au tableau ou pour
illustrer ce que peuvent être des représentations graphiques de
connaissances plus complexes.
first_order_type | |instance v -----web-------------- | | |subtype |subtype v v static_web <---exclusion--- web_2.0 | | |instance |instance v v static_WWW WWW_2.0
Insuffisances du Web classique dues à son peu de méta-données/organisation/sémantique:
- recherches sur des informations peu/in-organisées -> résultats
redondants, qui doivent
être interprétés et combinés par l'homme (seuls des
traitements lexicaux ou structurels
peuvent être appliqués), (faible) ratio
rappel/précision ou
précision/rappel
[precision/recall],
recherches sensibles au vocabulaire utilisé, ...
- faible interopérabilité et flexibilité des logiciels et des
bases de données (et des bases de connaissances si peu de relations
existent entre les éléments de ces bases pour relier ces
éléments).
Note: recherches à base de mot-clés avec des listes de
documents/paragraphes/phrases pour résultats
[document retrieval / question answering] ->
(faible) ratio rappel/précision ou précision/rappel, redondances et
inorganisation,
même si des techniques (automatiques) d'extraction de connaissances sont
appliquées (e.g., analyse terminologique/syntaxique/sémantique
du langage naturel).
Jusqu'en 2015, Google utilisait la BC
Freebase
mais ne faisait que de la recherche de documents :
il ne répondait pas
de manière précise à des questions précises.
Pour avoir des résultats organisés [knowledge retrieval/browsing],
il faut que les auteurs des diverses informations les relient (organisent)
entre elles par des relations sémantiques.
Même dans le futur, des techniques automatiques plus avancées ne
pourront extraire ce qui n'a pas été écrit ou représenté.
Questions de contrôle (après réponse aux questions
éventuelles des étudiants):
1. La recherche de documents va t-elle beaucoup s'améliorer dans le futur ?
Si oui, pourquoi ?
2. La recherche d'informations précises va t-elle beaucoup s'améliorer ?
Pourquoi/comment ?
1. Non, la "Note:" ci-dessus explique pourquoi;
2. Oui, le 1er paragraphe de cette page - et ce cours en entier - expliquent pourquoi.
World Wide Web Consortium (W3C):
comité international développant les standards du
WWW. Son portail inclut un
portail pour le Web sémantique et ses
technologies principales standardisées:
- la "famille d'ontologies de langages" OWL,
une extension de l'ontologie RDFS, un vocabulaire pour spécifier quelques
relations
sémantiques élémentaires telles que
"sous-type de" ("subClassOf" en RDFS) et
"instance de" ("type" en RDFS),
- le modèle de données RDF qui force les
documents RDF/XML ("RDF linéarisé|sérializé avec XML)
à suivre la convention de
linéarisation et normalisation de XML dite "alternating"|"fully striped"
afin de rendre les structures de données plus (ré-)utilisables ; lire le document
"Why RDF model is different from the XML model",
- des syntaxes (notations), e.g.,
RDF/XML (linéarisation de RDF avec XML),
RDFa
(pour stocker des connaissances très simples dans des tags HTML),
Turtle (syntaxe simple),
Notation3
(alias N3, une extension de Turtle),
SPARQL
(une extension de Turtle pour l'interrogation et la mise à jour de bases RDF)
- le mécanisme de conversion syntaxique GRDDL
basé sur des schémas de transformation
(typiquement en XSLT) fournis par les fournisseurs d'informations,
- les ontologies complémentaires
POWDER
(pour une description élémentaire de ressources),
SAWSDL
(pour une description élémentaire de services),
SKOS
(pour l'organisation de termes informels) et
RIF
(pour l'écriture de règles).
Les couches du Web sémantique selon le W3C:
 |
Note: RDF/XML n'est plus obligatoire et, à terme, va cesser d'être la norme de-facto (Turtle pourrait le devenir). |
Question de contrôle (après réponse aux questions
éventuelles des étudiants):
1. représentez (graphiquement puis en FL) les relations sous-type et exclusion
qui existent entre RDF, RDFS, RDF/XML, RDFa, Turtle,
N3, SPARQL et
les supertypes communs de ces types;
2. expliquez pourquoi le modèle RDF est différent du modèle XML,
et
donnez un moyen de voir si un modèle/langage
est plus souple et puissant qu'un autre ?
//1) solution (étendue) en FL:
KRL_element
> excl{
(language_ontology
> (OWL > (OWL-Full part: 1..* OWL-DL)
(OWL-DL part: 1..* OWL-Lite, logic: SHOIN)
(OWL-Lite part: 1..* RDFS, logic: SHIF)
(OWL_2 logic: SROIQ)
(RDFS part of: 1..* OWL-Lite)
)
(data_model > RDF)
(KRL_syntax > excl{ RDF/XML RDFa
(N3 part of: 0..* SPARQL)
(SPARQL part: 1..* Turtle)
(Turtle part of: 0..* SPARQL 0..* N3)
}
)
(logic > (description_logic
instance: SROIQ SHOIN SHIF,
part of: First-order_logic
),
instance: First-order_logic
)
};
//2) Le modèle de XML (ou des BDD, ou des approches orientées objet) est un
modèle d'arbre dont les noeuds sont implicitement reliés par des relations
de type "part" et peuvent être typés ou avoir des attributs. Il y a donc
seulement 3 types de relations possibles : partie, type, attribut).
Ainsi, le modèle de XML
- oblige ses utilisateurs à effectuer des choix arbitraires (e.g.,
mettre la classe d'objet Employee dans Employer, ou inversement),
- n'encourage pas (et donc aussi, ne force pas) la représentation
explicite (i.e., comme des entités du 1er ordre) des relations
entre objets; un utilisateur peut néanmmoins employer XML (ou une
approche orientée objet) pour définir et utiliser un modèle de
graphe, i.e., pour définir et n'utiliser que des classes d'objets
comme Concept et Relation.
RDF est un modèle de graphe qui permet de créer des relations typées entre
des individus ou types de concepts. En effet, il déclare des types d'objets
tels que "ConceptNode" et "RelationNode" (cf. 0.s.BDD).
Ainsi, il force ses utilisateurs à les utiliser et donc à représenter
des informations de manière plus précise et flexible qu'avec XML.
E.g., tout autre utilisateur peut, à tout moment, ajouter de nouveaux types
de concept/relation et les utiliser conjointement avec/sur les objets déjà
existants; il n'y a pas de schémas de données fixe/prédéfini.
Un modèle/langage est plus souple et puissant qu'un autre s'il inclut plus de
composants ou si ses composants permettent de définir les composants de l'autre.
Objet lexicalement formel: objet (d'information) lexicalement unique dans les fichiers où il est déclaré ou utilisé. Un URI est un objet lexicalement formel car c'est un terme unique à l'échelle du Web (c'est un "identifiant global" dans un format standard du Web). Une façon de rendre un terme lexicalement unique est de le préfixer ou postfixer par un identifiant de sa source. E.g., en N3, pm:bird réfère à un objet dont la source est identifié par pm (qui peut être une abréviation pour Philippe Martin, l'auteur de ce document). pm:bird réfère à sens particulier du mot "bird" pour pm. Dans les LRCs de WebKB, e.g., en FE et FCG, la syntaxe à utiliser n'est pas pm:bird mais pm#bird ou bird%pm.
Objet (sémantiquement) formel: objet dont la source a
déclaré qu'il avait un sens unique, en utilisant un LRC et/ou en lui
donnant une définition précise.
Pour avoir un sens unique, cet objet doit aussi être lexicalement unique
(dans les fichiers où il est déclaré ou utilisé).
Si l'objet formel est une description, il doit être composé uniquement de
symboles formels.
Un objet non formel peut être informel ou semi-formel (détails plus loin).
Terme formel [formal term]:
terme déclaré ou défini comme ayant un sens unique par sa source.
S'il est défini, il est possible qu'il n'ait pas d'identificateur;
dans ce cas, il s'agit d'une définition anonyme (lambda-abstraction).
Un URI est un terme unique à l'échelle
du Web (i.e., c'est un "identifiant global") et dans un format standard.
Toutefois, un URI n'est un terme (sémantiquement) formel que si son créateur a
précisé à quelle chose unique cet URI réfère,
e.g., à un document unique ou bien l'objet que ce document décrit.
Un terme formel réfère à une catégorie [category], i.e.,
- soit à un individu [individual] (un objet qui ne peut avoir d'instance;
les types qui ont pour instances des individus sont des types du 1er ordre),
e.g., pm#Paris__capitale_de_la_France_en_2010 ou toute instance d'un type de relation
- soit à un type de concept [concept type] ("classe" en RDFS), e.g.,
pm#capitale_de_la_France et
n'importe quel (représentant d'un des) sens du mot "bird";
note: rdf#property (alias, owl#property, sumo#binary_predicate,
pm#binary_predicate_type)
est
un sous-type de pm#relation_type qui est un sous-type de pm#1st_order_type qui est le
type de tous les types du 1er ordre (d'où son nom) et qui est donc un type
du second ordre
- soit à un type de relation [relation type] ("propriété" en RDFS),
e.g.,
pm#parent et pm#auteur.
Terme informel: mot (ou expression non quantifiée) lexicalement ou
sémantiquement ambiguë, i.e., ayant plusieurs sens.
Dans les langues naturelles comme l'anglais, la plupart des mots sont ambigus.
De plus, le contexte est souvent pris en compte pour omettre
des précisions, e.g., le mot "chambre" est souvent utilisé sans
préciser s'il s'agit d'une chambre d'hôtel, funéraire,
d'enregistrement, d'appareil photographique, etc.
Dans les LRCs, les termes informels sont souvent représentés entre
double quotes. Par exemple, dans les LRCs de WebKB, "bird" et en#"bird",
réfèrent respectivement à la chaîne de caractères
"bird" et au mot anglais "bird".
Dans le cadre de ce cours, les doubles quotes doivent être utilisées
pour encadrer les objets informels.
Questions de contrôle (après réponse aux questions
éventuelles des étudiants):
- en FE, FCG et RDF, les termes suivants sont-ils formels: "hat", pm#hat, hat%pm, pm:hat
- les termes suivants peuvent-ils (normalement, d'après leur nom en
français) référer
à un type de concept, à un type de relation, à un individu:
"hat", pm#Paris, pm#person, pm#type_de_relation_transitive, pm#relation, wn#part.
- reliez les termes suivants par des relations de type pm#instance, pm#equal ('='),
pm#subtype ('>') et pm#extended_specialization ('.>': toute relation de
spécialisation qui
n'est ni une relation sous-type, ni une relation instance):
en#"city", wn#city, wn#capital, en#"Paris",
wn#Paris___the_French_capital,
pm#Paris_the_city_which_was_the_French_capital_in_2010, pm#Paris_in_1860.
en#"city"
.> (en#"Paris" .> wn#Paris___the_French_capital)
(wn#city
> (wn#capital
pm#instance:
(wn#Paris___the_French_capital
= pm#Paris_the_city_which_was_the_French_capital_in_2010,
.> pm#Paris_in_1860 //the Paris of 1860
)));
//if we assume that en#"Paris" refers to only 1 individual,
// the current French capital,
//then en#"Paris" = wn#Paris___the_French_capital
// and the above representation can be precised as follows:
en#"city"
.> (wn#city
> (wn#capital
pm#instance:
(wn#Paris___the_French_capital
= pm#Paris_the_city_which_was_the_French_capital_in_2010
en#"Paris",
.> pm#Paris_in_1860
)));
Quantificateur de la logique du premier ordre:
quantificateur existentiel (-> "un" ["a"], "il existe",
"au moins 1", "1..*") et
quantificateur universel (-> "quelque soit" ["for all"],
"chaque" ["every", "each"]).
Quantificateur numérique: individuel (e.g., "2", "au moins 2",
"entre 2 et 35") ou statistique (e.g, "35%", "au moins 60%").
Phrase: observation ou bien définition.
Définition d'un terme T: phrase quantifiant universellement T sauf que,
contrairement à une observation, une définition n'est ni vraie ni fausse,
elle ne fait que définir un terme (cf. cet
exemple).
Phrase bien formée [well-formed statement]: phrase conforme à une
syntaxe, e.g., la syntaxe d'un LRC (donc directement interprétable dans une
logique) ou la syntaxe d'un langage naturel. Toute phrase bien formée est
- soit une définition (e.g., une procédure en Java),
- soit (la représentation d')une croyance (e.g., une observation, une
préférence, une théorie).
Par exemple, "un carré est un rectangle" est une définition
(de "carré"), alors que
"(apparemment / il se trouve que) les oiseaux volent" est une croyance.
Une phrase peut être composée de plusieurs sous-phrases explicitement
connectées par des relations sémantiques ou implicitement
connectées par une relation "et".
Une phrase relie des objets par des relations sémantiques ou lexicales.
Questions de contrôle (après réponse aux questions
éventuelles des étudiants):
1) les phrases suivantes ont-elles plus de chances d'être des définitions que des croyances:
"les arbres ont des feuilles", "un chanteur chante", "cette phrase est fausse";
2) les phrases suivantes sont-elles bien formées en français:
"Un chapeau.", "Les idées colorées dorment furieusement.",
"Regarde !".
//solutions: 1) non, oui, non 2) non, oui, oui
Multiplicité (d'une relation entre des types): spécifications
indiquant le nombre possible de relations entre des instances anonymes de ces types.
Par abus de langage, une multiplicité est plus souvent appelée
"cardinalité", mais une
cardinalité est en réalité
le nombre de relations du même type entre des
instances de types. Voici quelques exemples:
- dans "any bird is agent of a flight",
la multiplicité est "any -> 1..*"
(ou "any -> a" ou, en raccourci, "a").
- dans "every man has for part 0..* leg", la multiplicité est "every -> 0..*"
(ou, en raccourci, "0..*").
- dans "Philippe_Martin has for part 2 leg", la cardinalité est
"any -> 2" (ou, en raccourci, "2").
Note: le noeud source de la relation doit comporter un quantificateur universel ou
l'indication d'une définition (en FE/FL/FCG, il s'agit respectivement
de "every" et "any").
Dans "2 bird have for part a wing", il n'y a pas
de multiplicité puisque pour "part", on n'a pas "any->2" mais
"2->a" (ici "2" est un quantificateur numérique).
Dans les logiques de description
(et donc dans OWL), les multiplicités peuvent être
représentées mais pas les (autres) quantificateurs numériques.
De manière similaire, OWL et la plupart des logiques de description
permettent de définir des types ("classes" en RDFS) mais ne possèdent
pas de quantificateur universel (ces logiques obligent donc à utiliser des
définitions pour représenter des observations, ce qui est parfois
problématique).
Ci-dessous, 2 exemples en En, FE, FCG et N3. En : By definition, any man owns 2 hats. //définition certes fort peu commune FE : any man is owner of 2 hat. FCG: [any man, owner of: 2 hat]; N3 : owner_of owl:inverseOf owner; owner_of_2_hats owl:equivalentClass [a owl:Restriction; owl:onProperty owner_of owl:cardinality 2; owl:allValuesFrom hat]. man rdfs:subClassOf owner_of_2_hats. En : there are two men who own a hat. FE : 2 man are owner of a hat. FCG: [2 man, owner of: a hat]; N3 : a man owner_of [a hat]; different_from [a man owner_of [a hat]]. N3 : two_men a set; size 2. @forAll :m . { :m a man; is member of two_men } => { :m owner_of [a hat] }.
Exercice de contrôle (après réponse aux questions
éventuelles des étudiants):
représenter en En, FE, FCG et N3 les 3 phrases suivantes
et dire s'il est possible de les représenter en utilisant OWL:
- apparemment, tout oiseau a 2 ailes.
- par définition, tout oiseau a 2 ailes.
- 2 oiseaux volent.
//solution en N3 pour la 2ème phrase:
N3: wing_part rdfs:subPropertyOf part;
rdfs:range wing.
bird rdfs:subClassOf [a owl:Restriction;
owl:onProperty wing_part owl:cardinality 2;
owl:allValuesFrom bird].
Noeud (ou expression): un terme associé à un quantificateur;
de plus, un noeud est soit
- un "noeud concept" si le terme est un type de concept (alors appelé type de
ce noeud)
ou bien
un individu (dans ce cas, le quantificateur est omis ou ignoré), e.g.,
"a cat", "every French bird", "chaque pm#Paris_capitale_de_la_France";
- un "noeud relation" si le noeud permet de créer une relation (comme dans un
graphe)
entre plusieurs noeuds concept (ou depuis un noeud concept si
la relation est unaire);
dans ce cas le quantificateur est existentiel (il est souvent omis) et
le terme doit être un type (presque tous les LRCs obligent à ce que
cela soit un
type de relation), e.g., "color:" dans "a hat, color: a red".
Langage de représentation de connaissances (LRC):
langage permettant d'écrire des "représentations de connaissance",
i.e., des phrases ayant une interprétation dans une logique.
Un LRC a généralement un seul
modèle de données (modèle structurel) (qui décrit
les composants du langage et comment ils peuvent s'agencer) et
une seule notation textuelle ou graphique (syntaxe permettant d'écrire
des phrases textuellement ou graphiquement).
Une notation a une grammaire permettant de décider si une phrase est
structurellement correcte ou pas.
Tout modèle structurel et notation de LRC a une interprétation dans
une logique.
Il peut y avoir de nombreuses notations pour un même modèle ou une
même logique.
Note: la section 0.s.1erOrdre rappelle ce qu'est un(e)
entité/type/phrase/logique/notation d'ordre 0, 1, 2..*.
Objet sémantique: objet dont le ou les sens ("le sens" si l'objet est
formel) a été au moins partiellement défini (par rapport à
d'autres objets) via des "relations sémantiques" avec un LRC.
E.g., compte-tenu de la définition des relations
sémantiques pm:subtype (inverse de rdfs:subClassOf) et rdfs:instanceOf,
si pm déclare pm:domestic_cat comme pm:subtype de pm:cat,
et pm:cat comme pm:subtype (sous-type) de pm:feline,
alors tout individu déclaré comme étant une instance de
pm:domestic_cat est aussi (transitivement) déclaré comme étant
une instance de pm:feline et hérite des propriétés associées
à pm:feline.
Exemple de représentations en FL, FCG et N3:
FL : pm#domestic_cat < (pm#cat < pm#feline);
FL : pm#domestic_cat pm#supertype: (pm#cat pm#supertype: pm#feline);
FCG: [pm#domestic_cat, pm#subtype of: (pm#cat pm#supertype: pm#feline)];
N3 : pm:domestic_cat rdfs:subClassOf [pm:cat rdfs:subClassOf pm:feline].
L'origine de la dernière relation de type rdfs:subClassOf est pm:cat,
sa destination est pm:feline.
Note: une relation de type pm#subtype relie des types, pas des individus, il n'a
donc pas besoin de quantifier ces types.
Relation sémantique: "noeud relation" sémantique plus les objets
directement reliés par ce noeud relation.
Une relation sémantique peut être utilisée pour relier des
objets formels mais peut aussi être utilisée pour relier des objets
non complètement formels. Dans ce dernier cas, tous les sens de chaque objet
sont reliés à tous les sens des autres objets.
Exemples de classes de relations sémantiques de base:
relations d'équivalence,
généralisation [e.g., logical deduction, supertype, instance_of,
more_general_term],
sous-partie [e.g., sub_process, substance, physical_part],
thème [e.g., agent, object, recipient, instrument], argumentation,
contextualisation spatiale/temporelle/source [e.g., place, duration, date, author].
Cliquez ici pour une liste de types de relations.
Une relation sémantique est orientée et peut être unaire, binaire,
ternaire, etc.
Si elle est binaire, elle a un seul noeud origine et un seul noeud destination.
Le modèle RDF ne propose que des relations binaires et utilise le vocabulaire
suivant:
"relation sémantique"->[triplet], //i.e., le W3C parle de "triplets" pas de relations
"noeud relation"->[predicate], //terme hérité de la logique des prédicats (1er ordre)
"type de relation"->[property], //très mauvais choix du W3C car
// - le terme ne rappelle pas qu'il s'agit d'un type, et
// - une relation n'appartient pas à un objet et n'en est donc pas une propriété
"noeud origine"->[(predicate) subjet / (property) domain],
"noeud destination"->[(predicate) object / (property) range].
Relation lexicale: objet formel ne pouvant être utilisé
qu'entre des symboles informels.
Une relation lexicale n'est donc pas une relation sémantique.
E.g.: homonyme, antonyme, les relations entre chaînes de caractères, ...
Commande dans une BC: i) "phrase affirmée" dans une BC, ou bien ii) requête dans/sur une BC (pour obtenir une information ou l'exécution d'un processus).
RC informelle: RC utilisant uniquement des objets informels sauf éventuellement pour indiquer la source de la phrase. E.g., en Formalized English (FE), u1#u2#"birds fly" est une phrase informelle interprétée/traduite par u1 à partir d'une ou plusieurs phrases de la source u2.
RC formelle: (représentation de) connaissance (RC) utilisant uniquement des objets formels. E.g., en FE, u1#`any u1#bird is pm#agent of a pm#flight´ est une phrase formelle et une définition partielle par u1 de u1#bird : elle spécifie que pour être un u1#bird, une condition nécessaire est de voler (en permanence).
RC semi-formelle: RC utilisant des objets formels et informels.
E.g., en FE, u2#`every u1#bird is pm#agent of a flight´
est la croyance semi-formelle ("flight" étant informel) de u2 selon laquelle
"chaque u1#bird vole". Un autre exemple en FE:
u3#` u3#every_daylight__birds_flies_during_it
= `every "daylight" ?t `every u1#bird is pm#agent of
a "flight" with pm#time ?t´ ´ ´.
Ce dernier exemple est une définition par u3 du terme
u3#every_daylight__birds_flies_during_it comme référant à une
phrase non encore affirmée (dans la BC) représentant de façon
semi-formelle que "chaque jour, chaque oiseau vole tant qu'il fait jour".
Peu de LRCs permettent de représenter des objets informels ou semi-formels.
Méta-phrase: phrase dont au moins un objet est une phrase.
E.g., "John pense que 'il fait beau' ", `Tom#birds_fly = John#"birds fly"´
et "Cette phrase est fausse".
Phrase contextualisée: phrase + ses méta-phrases contextualisantes associées.
Méta-phrase contextualisante: méta-phrase spécifiant
des conditions (e.g., date, place) pour que la ou les phrases objets soient vraies.
Exemple: `Tom is believer of ` `Mary liking him´ in 2003´ ´
Non-exemple: `Tom#birds_fly = John#"birds fly"´.
Contexte d'une phrase: toutes les méta-phrases qui directement ou non, la contextualise. Il est souvent difficile/impossible de représenter tout le contexte d'une phrase: une description ne peut souvent qu'être partielle.
Ci-dessous, un exemple en En, FE, FCG, N3 et KIF.
//Exceptionally, for readability reasons, an action ("liking") is used as a relation En : Tom believes Mary likes him (now) in 2003, and that before she did not. FE : Tom is believer of ` ?p `Mary is liking Tom´ at time 2003´ and is believer of `!?p has for successor_time 2003´. FE : Tom#` ?p `Mary is liking Tom´ at time 2003´. Tom#`!?p has for successor_time 2003´. //Alternatives for the last sentence : // Tom#`!?p has for time_a_time_before 2003´ //this is not a classic relation // Tom#`!?p has for time a time that has for successor 2003´ FL : [Tom believer of: [?p [Mary agent of: (a liking object: Tom)] time: 2003], believer of: [!?p successor_time: 2003] ]; N3 : { :p {[a :Liking; :agent :Mary; :object :Tom]} :time "2003"} :believer :Tom. :not_p negation :p. {:not_p :successor_time "2003"} :believer :Tom. KIF: (exists (?p) (and (= ?p '(exists ((?l liking)) (and (agent ?l Mary) (object ?l Tom)))) (believer ^(time ,?p 2003) Tom) (believer ^(successor_time (not ,?p) 2003) Tom)))
Question de contrôle (après réponse aux questions éventuelles des étudiants):
- représentez en En, FE, FCG et N3 la phrase suivante
"Tom croit qu'il est possible qu'il aime Mary".
FL: [Tom may be agent of: (a love object: Mary)] believer: Tom
FL: [ [Tom agent of: (a love object: Mary)]
modality: a situational_possibility
]
believer: Tom;
//Examples of modalities: situational_possibility (<- "may be/do"),
// physical_possibility (<- "can do"),
// deontological_necessity (<- "should/must do"),
// psychological_necessity (<- "compelled to do")
Représentez dans le LRC que vous souhaitez
-- après l'avoir précisé -- et en respectant les règles
de modélisation données en cours, la phrase
"If a student S does not ask a teacher about a point P at a time T, this is because
he (S) has understood this point before T or he does not want to learn P".
Notes :
- pour représenter le "or", utilisez une relation de type "or" entre 2 phrases,
- rappelez vous qu'une relation est une phrase,
- en FL, 14 relations (dont 2 relations de type "time") suffisent pour la
représentation demandée (→ 3 à 5 lignes);
vous avez déjà vu plusieurs fois en cours
les autres relations nécessaires.
FL: [ [a student ?s not agent of: (a asking recipient: a teacher, object: a point ?p)]
time: ?t ]
=> [ [ [?s agent of: (an understanding object: ?p)] time: (?t2 successor: ?t) ] or:
[?s not agent of: (a wanting object: [?s agent of: (a learning object: ?p)]) ]
]
Représentez dans le LRC que vous souhaitez
-- après l'avoir précisé -- et en respectant les règles
de modélisation données en cours, la phrase
"Having read the E5_course is sufficient for a student to represent this phrase".
Notes :
- la solution à cet exercice ressemble
à celle pour l'exercice précédent
(avec 2 lignes au lieu de 4 ou 5),
- en FL, 4 relations suffisent pour la représentation demandée.
FL: [a phrase ?p [a student ?s agent of: (a reading object: the E5_course)]
=> [?s can be agent of: (a representing object: ?p)] ]
Rappels (du cours de GL et de systèmes d'information) à propos des entités/types/logiques d'ordre 0/1/2.
Entité du 1er ordre: élément d'information pouvant être mis dans une variable,
e.g., une fonction en C. Contre-exemples en C++ : un attribut, un résultat de fonction.
Plus vos modélisations (dont vos programmes) utilisent des entités de
1er ordre (ou lieu d'entités d'ordre 0), plus elles seront génériques
et donc facilement extentibles, paramétrable, (ré-)utilisables, ...
Pour cela, il vous faut donc utiliser des langages expressifs (-> logique d'ordre supérieur) et
des notations de haut niveau (cf. page suivante).
Type (d'ordre 1, 2, ...): élément d'information qui peut avoir au moins une instance,
e.g., pm#cat (qui pour instance pm#Tom_the_cat), pm#Type qui a pour instance pm#cat et le
type de relation '>'.
Individu (ou "type d'ordre 0"): élément d'information qui n'est pas un type,
e.g., pm#Tom_the_cat et `pm#mammal > pm#cat´.
Type du 2nd-ordre: type ayant pour instance un type du 1er ordre, lequel a pour instance un individu (catégorie ne pouvant être instanciée).
Logique d'ordre 0 (alias, logique propositionnelle):
logique n'ayant pas de variable (quantifiée).
Logique d'ordre 1 (alias, logique des prédicats, un type de prédicat étant assimilable à
un type de relation unaire ou non, ou encore à un type de concept ou un type de relation):
logique ou seuls les individus (explicitement nommés ou anonymes) peuvent
être quantifiées (et donc mis dans des variables),
e.g., la définition suivante est une "phrase du 1er ordre" et nécessite une logique du
1er ordre.
En : the relation "ancestor" is transitive since the ancestor of an ancestor is an ancestor. LP : instance(owl#Transitive_property, ancestor) <= ∀?x ∀?y ∀?z (ancestor(?x,?y) ∧ ancestor(?y,?z)) => ancestor(?x,?z) KIF : (<= (instance owl#Transitive_property ancestor) (forall (?x ?y ?z) (=> (and (ancestor ?x ?y) (ancestor ?y ?z)) (ancestor ?x ?z) )) )
Logique d'ordre 2..* (alias, logique d'ordre supérieur): logique où les types (de
concept/relation/quantification) peuvent être quantifiés,
e.g., la définition suivante est une "phrase du 2nd ordre" et nécessite une logique du second ordre
car elle comporte un quantificateur universel sur des relations.
En : ?r is a owl#Transitive_property ?r iff ?r(?x,?y) and ?r(?y,?z) implies ?r(?x,?z) LP : ∀?r owl#Transitive_property (?r) <=> ∀?x ∀?y ∀?z ( ?r(?x,?y) ∧ ?r(?y,?z) ) => ?r(?x,?z) KIF : (forall (?r) (<=> (owl#Transitive_property ?r) (forall (?x ?y ?z) (=> (and (?r ?x ?y) (?r ?y ?z)) (?r ?x ?z))) )) KIF : (defrelation owl#Transitive_property (?r) := (forall (?x ?y ?z) (=> (and (?r ?x ?y) (?r ?y ?z)) (?r ?x ?z))) ) FL : owl#Transitive_property (?r) := [ [^x ?r: (^y ?r: ^z)] => [^x ?r: ^z] ]; //^x, ^y et ^z are free variables, i.e., implicitely universally quantified FL : [__ every pm#relation ?r, every pm#thing ?x, every pm#thing ?y, every pm#thing ?z] [ [owl#Transitive_property ?r] <=> [ [?x ?r: (?y, ?r: ?z)] => [?x ?r: ?z] ] ];
Logique du 2nd-ordre: logique permettant de quantifier des relations/prédicats.
Définir la transitivité demande une logique du 2nd-ordre, mais définir une
relation transitive particulière (e.g., subtype) ne demande pas une logique du
2nd-ordre.
Seules certaines logiques du 2nd-ordre (e.g., logiques modales, logiques temporelles)
permettent de raisonner sur certaines phrases contextualisées (e.g., phrases
contextualisées dans le temps, phrases utilisant des opérateurs modaux) mais
écrire des méta-phrases ne requiert pas une logique du 2nd-ordre.
Exemple de moteur d'inférence du 2nd-ordre: CASL.
Exemple de moteur d'inférence du 1er-ordre: Otter.
Exemple de raisonnement nécessitant une logique modale:
la "preuve ontologique de l'existence de Dieu" de Gödel<-Leibnitz<-Anselm
(ensuite affinée par Anderson).
Notation du 2nd-ordre: notation permettant d'utiliser des variables pour les
relations/prédicats et de les quantifier. Une notation du 2nd-ordre n'implique pas
nécessairement un moteur d'inférence du 2nd-ordre pour l'utiliser, en
particulier si les phrases du 2nd-ordre sont des définitions.
En effet, il n'existe souvent qu'un nombre fini de catégories de 1er ordre
concernées par ces définitions et il est souvent possible
d'appliquer (instancier) la définition du 2nd-ordre à ces catégories
(e.g., instancier la notion de transitivité à chaque relation transitive).
Le moteur d'inférences peut alors ne pas prendre en compte la définition
du 2nd-ordre.
La même méthode peut souvent être utilisée pour transformer des
phrases du 1er-ordre en phrases n'utilisant que OWL-Full ou OWL-DL.
Il faut également noter que OWL-DL a des types du second-ordre (e.g.,
owl#transitive_property, owl#functional_property) qui sont exploités par les
moteurs d'inférences prenant en compte OWL-DL, sans que OWL-DL soit pour autant
une logique du second-ordre.
L'expressivité d'une BC - et donc ses caractéristiques vis à vis des
critères de complétude des raisonnements qui peuvent être effectués
via cette BC - n'est donc pas "déterminée" par la notation utilisée pour
rentrer les informations dans cette BC.
De plus, un moteur d'inférences peut toujours choisir de ne pas utiliser toutes
les informations de la BC. Il sera alors plus efficace mais ses résultats pourront
être incomplets ou non toujours valides. C'est un choix qui ne peut être
fait que dans le contexte d'une application. E.g., pour de la recherche d'information,
effectuer de simples recherches de spécialisations et/ou
généralisations par comparaisons de graphes est souvent suffisant.
Ainsi, pour de la recherche d'information, il est intéressant de retourner la
phrase "Les autruches ne volent pas" à la requête
"Est-ce que les oiseaux volent ?" même si ni "Les oiseaux volent" ni sa
négation ne sont des implications logiques de "Les autruches ne volent pas".
En conclusion, pour modéliser et partager des informations
générales (e.g., des phrases en langage naturel) il vaut mieux utiliser un
langage plus expressif que RDF+OWL/XML pour éviter de mal représenter ces
informations (e.g., représenter "par définition, un oiseau vole" au lieu de
"En France, en 2010, selon l'étude de Dr X, au moins 80% des oiseaux en bonne
santé sont capable de voler".
OWL et, plus généralement, les logiques de descriptions, sont des logiques
pour effectuer certains types de raisonnements de manière efficace ou, du moins,
dans des temps prédictibles. Adopter ces logiques est donc un bon choix pour
certaines applications mais n'est pas un bon choix pour un standard d'échange
d'informations comme RDF+OWL/XML se veut être.
Notation de haut niveau: notation qui permet de représenter des phrases générales de manière concises et normalisées (et donc dont les représentations expressives et normalisées sont généralement faciles à comparer, même par simple comparaison de graphes). Ceci implique (entres autres) la possibilité d'utiliser des contextes, des quantificateurs numériques et d'autres raccourcis (détails en section 4.1). FCG, FE et FL sont des notations de haut niveau. KIF est expressif mais n'est pas de haut niveau. Les notations utilisant le modèle RDF+OWL ne sont pas de haut niveau. Les notations ayant une syntaxe XML ne sont pas de haut niveau.
class Object : {/*...*/} ; class ObjectReference : {/*...*/}; //pointer, database id, ... class Quantifier : Object {/*...*/}; class Node : Object //concept (node) or relation (node) { RelationRefArray get_relations (/*rel. selection parameters*/); RelationRefArray set_relations (/*rel. selection parameters*/); // references to relations connected (from/)to this node, // directly or not ("directly" is a default in the parameters); //1 relation selection parameter is the relation type: subtype, // type, creator, ... (a relation "creator" is (implicitly or // not) about the node representation, not its semantic content) //A node that has a meta-statement (black/white context) // has a relation of type pm#meta-statement (note: any node // that is existentially quantified (e.g., a relation) is a // statement (and probably a sub-statement) and conversely ; // a statement is either a belief, definition or command (e.g. // a query). //A (concept) node that is a meta-statement has a relation of // type pm#first_node and/or pm#embedded_node (an n-ary relation) //1 other parameter should allow the selection of binary } // relations that are "from"/"to" this node class ConceptNode : Node //alias "concept" { //The code should not "know" that actually relations are stored // in concepts, or concepts are stored in relations, or neither. //Similarly, the code should not "know" that node quantifiers // are stored in nodes or in relations: QuantifierRef quantifier_get (/*rel. selection parameters*/); QuantifierRef quantifier_set (/*rel. selection parameters*/); //A node that is a formal/informal "term" (e.g., a word, a type, // a date, ...) has no/all quantifier(s). //A node that has a quantifier is not named (it is not a term). //A particular user is a term ; a set/class of users is not. } //A node may have for creator/believer a (set of) user(s). class RelationNode : Node //alias "relation" { //a relation has directly or indirectly related concepts NodeRefArray relatedConcepts_get (/*concept selection parameters*/); NodeRefArray relatedConcepts_set (/*concept selection parameters*/); QuantifierRefArray quantifiers_get (/*concept selection parameters*/); QuantifierRefArray quantifiers_set (/*concept selection parameters*/); //these are the quantifiers of the linked concepts; } //the existential quantifier of a relation is implicit
Lire OWL 2 Profiles et, en particulier, sa section 5: Computational Properties (+ rappel : décidabilité).
Inférence: méthode de raisonnement pour, à partir de connaissances (alors appelées "données" ou "faits" de l'inférence, qu'ils soient vérifiés ou non), générer une autre connaissance (alors appelée "résultat" de l'inférence). Lorsqu'une méthode n'est pas logique (et donc non sûre), son résultat doit être testée par rapport à des observations. Il existe quatre types principaux d'inférences: la déduction (seul type d'inférence logique), l'induction, l'abduction et l'analogie.
Déduction: méthode de raisonnement dont le résultat contient moins
d'information que les faits sources. Le résultat est donc sûr si les faits sont sûrs.
Le modus ponens est une règle de déduction logique. E.g.:
Données: Tweety is a bird. Every bird flies
(alias: if b is a bird, then b flies).
Résultat: Tweety flies.
Plus formellement: si "A implique B" et "A est vrai" alors "B est vrai" (modus ponens).
Induction: généralisation (non sûre) à partir d'exemples. E.g.:
Données: Tweety, Polly and Hooty are birds.
Tweety, Polly and Hooty fly.
Résultat: Every bird flies (alias: if b is a bird, then b flies).
Plus formellement: lorsque tous les exemples (d'instances) d'un objet A impliquent B,
l'induction suppose que toutes les instances de A impliquent B.
Abduction: génération d'une hypothèse pour expliquer un fait. E.g.:
Données: Tweety flies. Every bird flies (alias: if b is a bird, then b flies).
Résultat: Tweety is a bird.
Plus formellement: si "A implique B" et "B est vrai" alors "A est vrai".
Analogie: génération à partir de propriétés communes. Ces propriétés peuvent être trouvées par des méthodes statistiques et/ou de comparaison symbolique (comme illustré plus loin). L'analogie peut être vue comme une généralisation des autres types d'inférences, comme illustré par la figure suivante.


Note: dans son sens général, l'argumentation rassemble toutes les techniques utilisables pour convaincre. Les arguments utilisant la déduction sont logiques, les autres sont fallacieux.
Tous les moteurs d'inférences proposent un moyen de savoir si
une (phrase "proche" d'une) phrase particulière existe dans une BC,
ou peut être déduite de cette BC,
ou si sa négation ne peut être déduite de cette BC.
Pour permettre de spécifier de telles requêtes, divers opérateurs de recherche
peuvent donc être proposés; ils prennent en paramètre une "phrase requête".
Le langage de requête proposé peut ne contenir qu'un opérateur (qui peut
par exemple être noté "?" ou être implicite) mais peut proposer des moyens de
combiner diverses requêtes ou commandes.
Généralement, le langage de requêtes proposé est une extension du langage
proposépour affirmer des phrases.
Il est généralement plus facile pour un moteur d'inférences de gérer de
manière exacte et complète des requêtes exprimées avec une notation
pour une logique du 1er ordre que des
affirmations effectuées avec une notation pour une logique du 1er ordre.
Dans WebKB, le langage de requêtes/commandes est appelé FC (For Control).
Il propose divers opérateurs qui peuvent utiliser des phrases requêtes écrites
dans divers LRCs. Toutes les requêtes peuvent être écrites avec
l'opérateur "?", les autres opérateurs sont des abréviations.
Ci-dessous, quelques exemples commentés.
Lorsque non-explicitée, la notation ici utilisée pour les phrases requêtes est
FL.
À propos de '>=' (spécialisation), '.>=' (spécialisation étendue), '=>' et '<=>' entre phrases:
- '<=>' est l'équivalence logique entre phrases; entre termes, on utilise '='.
- `A .>= B´: B contient/représente plus d'informations que A, ou A = B.
- `A >= B´: idem sauf que A et B sont des formules logiques "simples",
i.e., existentielles conjonctives avec ou sans contextes négatifs,
i.e., utilisant ∃ et/ou ∧ mais pas ¬, ∀, ni de quantificateurs numériques.
Avec des formules "simples", on a: (A > B) <=> (B => A) <=> (A .> B)
De manière générale, on a seulement: (A > B) => ( (B => A) ∧ (A .> B) )
? [a pm#cat part: a paw] //-> réseau (et donc hiérarchie de spécialisation étendue) // des phrases de la BC qui impliquent ceci //Pas de réponse -> faux ?? [a pm#cat part: a paw] //renvoie True s'il y a au moins une réponse, False sinon ? [a pm#cat part: a paw] <= ?s //-> idem ?s [a pm#cat part: a paw] <= ?s //-> liste (et non réseau) des phrases impliquant [...] ? [a pm#cat part ^2..4: a paw] //-> chaîne de 2 à 4 relations "part" (avec leurs contextes // si elles en ont) reliant pm#cat à "paw" ? [a pm#cat part ^1..*: a paw] //-> chaîne d'au moins une relation "part" reliant pm#cat à "paw" ? [a pm#cat part ^+ : a paw] //idem (note: même si ceci est sans réponse, [a pm#cat part: a paw] // peut être vrai via d'autres définitions/règles/relations que des relations "part"; // en effet, le `^+´ étant une expression régulière sur des chemins de relations, // la recherche de réponse se fait par comparaison de graphes/chemins et non via // un mécanisme complet de déduction logique comme avec "<=") ? [a pm#cat part: a paw] <=^1 ?s //-> réseau des phrases directement et explicitement impliquantes ? [a pm#cat part: a paw] =>^1 ?s //-> 1 relation "=>" directe et explicite de [...] à ?s ? [a pm#cat part: a paw] =<^1 ?s //-> 1 specialisation directe et explicite de ?s à [...] ? [a pm#cat part: a paw] >=^1 ?s //-> réseau des phrases directement et explicitement spécialisantes ? [a pm#cat part: ?x] //-> réseau des phrases impliquant que pm#cat a des sous-parties ?x [a pm#cat part: ?x] //-> objets sous-parties de pm#cat ? [pm#cat >^1 ?x] //-> hiérarchie des sous-types directs de pm#cat ? pm#cat >^1 ?x //idem (car en FL, les [] de premier niveau sont optionnels) ? `pm#cat has for direct pm#subtype ?´ //idem avec la notation FE pour la phrase requête ? [pm#cat < ?x, > ?y] //-> hiérarchie des super-types et sous-types de pm#cat ?x,y [pm#cat < ?x, > ?y] //-> liste des super-types et sous-types, préfixés par "?x=" et "?y=" ? [pm#cat !pm#exclusion: ?x] //-> réseau des (phrases montrant les) termes non exclusifs à pm#cat ?s [pm#cat pm#part: 4 leg] !pm#exclusion: ?s //-> liste des phrases non exclusives à [...] ? [a pm#cat (pm#relation: a pm#thing)^1..3 pm#emplacement: fr#"France"] //-> chaîne de // 1 à 3 relations entre une instance de pm#cat et quelque chose ayant pour // pm#emplacement quelque chose qui en Français est appelé "France" ?3 [a pm#cat part: ?x] //renvoie au maximum 3 graphes réponses ?3:x [a pm#cat part: ?x] //renvoie au maximum 3 valeurs pour ?x ??:x [a pm#cat part: ?x] //renvoie True si ?x existe et si son quantificateur est différent de 0|no ?2..4:x [a pm#cat part: ?x] //renvoie au maximum 4 valeurs pour ?x ou aucune s'il n'y en a pas au moins 2 ??3:x [a pm#cat part: ?x] //renvoie True s'il y a au moins 3 valeurs pour ?x, False sinon
Note: ci-dessus, les expressions du type "quelles phrases de la BC impliquent ..."
réfère à des phrases "minimales" (car sinon, la BC pouvant
elle-même être considérée comme une (grosse) phrase,
la réponse serait la BC entière). Ici, "minimale" signifie "qui serait - ou pourrait
être - faux si un élément était omis".
Une phrase minimale inclut donc ses
phrases contextualisantes. Par exemple,
si la requête est : ? [a pm#animal pm#part: 4 leg] >=^1 ?s
et si la BC contient la phrase suivante :
[ [2 pm#cat pm#part: 4 ^(leg color: a yellow), owner: pm#Tom]
time: 21/12/2010]
alors une réponse est :
[ [2 pm#cat pm#part: 4 ^(leg color: a yellow)] time: 21/12/2010]
La précision "owner: pm#Tom" n'a pas à être incluse dans une réponse
minimale, par contre
il vaut mieux inclure précision "color: a yellow" car
Note: ci-dessus, les expressions du type "quelles phrases de la BC impliquent ..."
réfère à des phrases "minimales" (car sinon, la BC pouvant
elle-même être considérée comme une (grosse) phrase,
la réponse serait la BC entière). Ici, "minimale" signifie "qui serait - ou pourrait
être - faux si un élément était omis".
Une phrase minimale inclut donc ses
phrases contextualisantes. Par exemple,
si la requête est : ? [a pm#animal pm#part: 4 leg] >=^1 ?s
et si la BC contient la phrase suivante :
[ [2 pm#cat pm#part: 4 ^(leg color: a yellow), owner: pm#Tom]
time: 21/12/2010]
alors une réponse est :
[ [2 pm#cat pm#part: 4 ^(leg color: a yellow)] time: 21/12/2010]
La précision "owner: pm#Tom" n'a pas à être incluse dans une réponse
minimale, par contre
il vaut mieux inclure précision "color: a yellow" car
Exercice de contrôle
Si l'on suppose que la BC [KB] ne contient que
pm#relation > (part pm#type: pm#transitive_relation_type) pm#type pm#supertype;
B1 part _[every->a]: (B2 part _[every->a]: (B3 part _[any->a]: B4)), < A1, > C1;
//i.e.: B1 < A1, > C1; every B1 part: a B2; any B2 part: a B3; any B3 part: a B4;
quelles réponses doit donner un moteur d'inférences aux requêtes FL suivantes
s'il connait la sémantique de pm#transitive_relation_type, pm#type et pm#supertype ?
/*1.*/ ? [a B1 part: a B4] /*2.*/ ? [a B1 part ^1: a B4] /*3.*/ ? [a B1 part ^1: a ?x] /*4.*/ ?x [a B1 part ^1: ?x] /*5.*/ ? [a B1 part: a (?x < A1)] /*6.*/ ?x [a B1 part: ?x] /*7.*/ ? [B1 pm#relation ^1: a ?x] /*8.*/ ?x [B1 pm#relation ^1: ?x] /*9.*/ ? [B1 pm#relation: a ?x]
//Answers (at least with the "closed world assumption"): /*1.*/ every B1 part: (a B2 part: (a B3 part: a B4)); part pm#type: pm#transitive_relation_type; /*2.*/ []; //no answer /*3.*/ a B1 part: a B2; /*4.*/ ?x = a B2; //note: with "a ?x" in the query, the answer would have been: ?x = B2 /*5.*/ []; //no answer /*6.*/ ?x = a B2; ?x = a B3; ?x = a B4; /*7.*/ every B1 part: a B2; //ou: B1 part _[every->a]: a B2, < A1, > C1; pm#relation > part pm#type pm#subtype; /*8.*/ ?x = a B2; ?x = A1; ?x = C1; //since: pm#relation > (pm#type instance: A1 C1) /*9.*/ [every B1 part: (a B2 part: (a B3 part: a B4))] //note: with "?x" in the query instead of "a ?x", all the relations in this very // particular KB would have been good answers, since they either specialize the // query graph or they help find other answers which imply the query graph (as // illustrated in the answers /*1.*/ and /*7.*/ above). //Note: si la requête avait été ? [B1 relation ^0..2: a ?x] // la phrase [every B1 part: (a B2 part: a B3)] aurait-elle compté comme une chaîne de // 2 ou 3 relations ? I.e., aurait-on compté l'implcite relation de type pm#type dans // [a B2] (puisque [a B2] est équivalent à [a pm#thing type: B2]) ? // Pour des raisons pratiques, il vaut mieux que le choix par défaut soit "non" et // que chaque utilisateur ait un moyen de changer ce choix par défaut s'il le souhaite. // De même, il vaut mieux que, dans la recherche de chemins, les relations '<=>' ou '=' // soient utilisées mais, par défaut, ne soient pas comptés. // Ce sont donc les choix par défaut adoptés.
Jointure de deux phrases: création d'une 3ème phrase composée des deux phrases fusionnées (alias, jointes) sur certains noeuds, par exemple car ils sont identiques.
Jointure dirigée: les noeuds à joindre sont spécifiés en paramètre
de la jointure.
Un noeud joint est une spécialisation des deux noeuds à joindre.
E.g., une jointure de [a cat, place: a table] et
[Tom, place: some (furniture, color: a red)]
sur leurs premiers noeuds est:
[Tom, place: a table, place: some (furniture, color: a red)].
Jointure maximale: jointure non dirigée qui
- maximise le nombre de noeuds concept et/ou relation joints, et/ou
- minimise le nombre de noeuds concept et/ou relation dans la phrase résultante, et/ou
- sélectionne la zone/phrase jointe la plus spécialisée.
Il peut bien-sûr y avoir plusieurs solutions alternatives dans chaque cas.
E.g., une jointure maximale de [a cat, place: a table] et
[Tom, place: some (furniture, color: a red)] est:
[Tom, place: some (table, color: a red)].
Note: un langage de script similaire au shell d'unix peut être utilisé pour combiner
des commandes.
C'est le cas avec le langage FC (For Control) de WebKB. E.g.:
if (? [a cat])
then ? [a pm#cat] <= ?s | maximal_join
fi //jointure maximale des phrases de la BC qui impliquent l'existence d'un pm#cat
Ontologie de langage (de représentation de connaissances) (e.g., RDFS, OWL, ...): ontologie formelle dont les termes décrivent un modèle de données (+ logique/sémantique) utilisable pour représenter des connaissances. E.g., binary relation, subtype, cardinality, ...
Ontologie lexicale (alias, de langage naturel) (e.g., à partir de WordNet): ontologie dont les termes formels représentent le sens de termes informels d'un langage naturel.
Ontologie de haut niveau (e.g., DOLCE): ontologie dont les termes formels représentent des distinctions générales (e.g., entité, situation, space, time, part-of, ...) généralement utiles pour organiser/contrôler toute ontologie qui n'est pas une ontologie de langage.
Ontologie fondamentale [fundational ontology]: ontologie formelle de haut niveau dont les termes sont très précisément définis et, le plus souvent, sont relatifs à un seul thème, e.g., relations spatiales/temporelles/partie-de.
Ontologie de domaine: ontologie dont les termes sont relatifs à un domaine, e.g., la radiographie, l'élevage des poules, ...
Tâches:
- évaluation des différentes contraintes (buts, compétences,
ressources, ...)
- extraction et modélisation de connaissances dans une BC
- développement+validation d'un SBC et intégration à d'autres outils
- maintenance, révisions, évaluations.
Bibliothèque de (modèle de) tâches génériques:
décomposition de tâches (classiques pour la résolution de
problème) en méthodes (chaque méthode est une façon
d'exécuter une tâche) et décomposition de chaque méthode
en sous-tâches (il s'agit d'un modèle de tâche).
La bibliothèque de la méthodologie
KADS-I (pour
l'acquisition des connaissances et la création de SBCs)
offrait des modèles de tâches pour des
tâches d'analyse (e.g., prédiction, surveillance, diagnostic, évaluation),
de modification (e.g., planification, configuration) et
de synthèse (e.g., modélisation, conception, reconstruction).
Dans KADS-II, afin de faciliter la réutilisation et la combinaison des
modèles de tâches, les auteurs de KADS se sont focalisés sur les
tâches génériques les plus primitives (en anglais:
assignment, planning_and_reconstruction, modeling, design, modeling, prediction,
assessment, correction, monitoring, diagnostic, repair).
Sous-tâches de
"modélisation|analyse|spécification & conception" de logiciel :
- analyse & spécification des besoins
--> modèle|schéma conceptuel
- conception du logiciel et de ses bases d'informations
--> modèle de conception
Cycle de vie en "ingénierie des connaissances" (Heijst & al., 1996) :
Hiérarchie de spécialisation sur les "tâches génériques" dans
la "méthodologie d'acquisition des connaissances"
KADS-I (Breuker & al., 1987)
(tâches dont les "modèles génériques" sont à
sélectionner, suivre et combiner
lors de l'élicitation et modélisation de connaissances
-> méthodologie "dirigée par les modèles" et donc "descendante") :
analyse_de_système identification (d'une catégorie) classification classification_simple diagnostic (identification d'une catégorie de faute) diagnostic_faute_unique diagnostic_par_classification_heuristique (modèle du domaine : modèle de faute) diagnostic_systématique (modèle du domaine : modèle de rectitude) localisation_structurelle localisation_causale diagnostic_fautes_multiples évaluation (de correspondance ou d'adéquation : identification d'une classe de décision) surveillance (identification d'une incompatibilité entre une norme et une observation) prédiction (d'un état passé ou futur du système) prédiction_de_comportement prédiction_de_valeurs modification_de_système réparation remède contrôle maintenance synthèse_de_système transformation conception conception_par_transformation conception_par_raffinement conception_par_raffinement_à_flot_unique conception_par_raffinement_à_flots_multiples configuration planification modélisation
Diagnostic systématique" dans KADS-I :
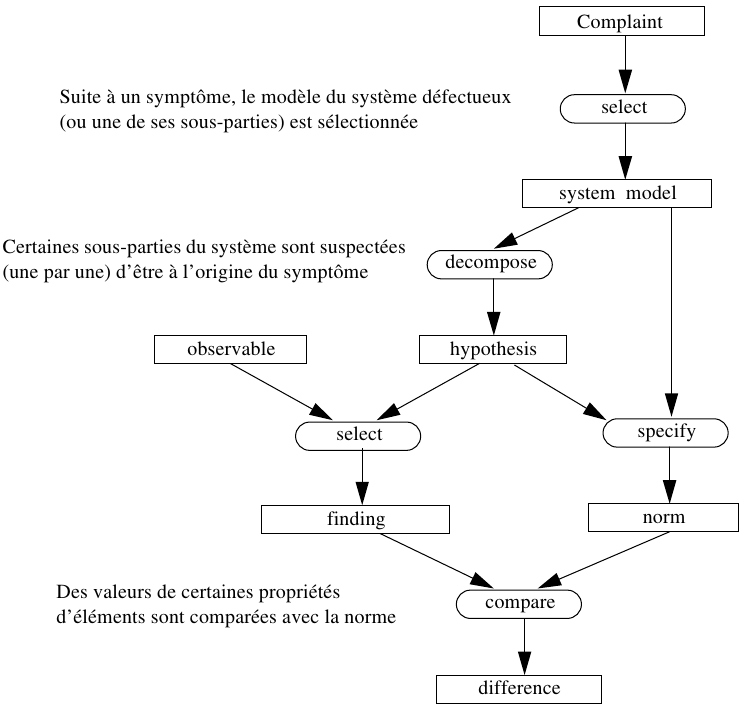
En théorie, dans KADS (et dans d'autres méthodologies),
une tâche ne se
décompose pas directement en sous-tâches :
une tâche est un but qui a des méthodes alternatives pour être atteint
et chaque méthode définit une décomposition en sous-tâches.
Le choix entre différentes méthodes pour une tâche est souvent fait
lors de la
modélisation, en fonction des contraintes de l'application visée.
Toutefois, lorsque cela est possible, il est préférable de modéliser la
façon d'effectuer
un tel choix pour que le SBC final puisse l'effectuer dynamiquement en fonction des
informations dont il disposera.
Il s'agit alors de modéliser une tâche qui
effectue des choix entre des méthodes.
Le choix de l'ordre entre des sous-tâches d'une méthode est le plus souvent
déterminé dynamiquement en fonction des diverses contraintes
statiques (e.g., relations entre les tâches) et
dynamiques (données fournies lors
d'une exécution).
Ce choix peut être effectué par le "moteur d'inférences sur
règles (déclaratives)" utilisé, ou peut être modélisé
dans une tâche séparée,
e.g., une tâche de planification [planning, scheduling].
Dépendance entre les "tâches génériques" dans
CommonKADS (Breuker, 1994) :

L'élicitation et modélisation des connaissances, i.e.,
la construction de modèles de tâches et d'objets utilisés par ces
tâches, peut être
- "dirigée par les modèles" et donc "descendante"
- "dirigée par les données" (interviews/articles d'experts, ...) et donc "ascendante"
- mixte (de manière opportuniste ou systématique).
Avec la popularisation du
Web sémantique
(liée à la prise de conscience des limites
du Web classique et, plus généralement, des nombreux problèmes liés au peu de
prise en compte des relations sémantiques dans les approches GL/BDD classiques),
les méthodologies de modélisation|analyse|spécification & conception de logiciel
prennent de plus en plus en compte les résultats des méthodologies de
modélisation de connaissances.
Toutefois, actuellement, cette prise en compte reste limitée. Ainsi, ce qui est appelé
"dirigée par les modèles" dans les 1ères méthodologies (celles pour le logiciel)
correspond à ce qui est appelé "dirigée par les données" dans les 2ndes.
A partir d'une section similaire
à celle-ci, le cours de Génie Logiciel a introduit
- et partiellement fusionné - les 2 types de méthodologies
(puisque les 2ndes généralisent les 1ères et simplifient leur apprentissage)
mais il ne donnera pas d'exercice (ni d'évaluation) sur les modèles de tâches.
Par contre, les définitions liées à "tâche" (e.g., le lien entre
"tâche" et "méthode")
pourra faire l'objet d'évaluations.
Entité d'information [information entity]: objet(s) qui sont/contiennent
de l'information ou permettent d'exprimer/rechercher de l'information.
Deux spécialisations non exclusives de "entité d'information" sont:
"contenu de description" et "instrument de description".
Contenu de description [description content]: affirmation/requête d'information et donc les objets suivants (tels que définis précédemment): commande, information, phrase affirmée, croyance, définition, donnée, connaissance, web.
Instrument de description [description medium]: objet(s) permettant de décrire de l'information et donc les objets suivants (tels que définis précédemment): langage, phrase non encore affirmée, symbôle, élément graphique, terme, identificateur, URI, quantificateur, catégorie (individu ou type de concept/relation).
La page suivante présente une organisation formelle (en FL) des
"types de concept" de haut-niveau les "plus importants" dans le sens où
ce sont ceux qui
- sont le plus intuitifs à utiliser pour catégoriser des sens de mots
(contrairement à, par exemple, "abstrait", "divisible", ...),
- ont le plus de liens d'exclusion entre eux (donc ceux qui permettent le
plus de
détections d'erreur de modélisation)
- sont le plus facilement utilisables pour des signatures de
"type de relations" primaires (i.e., non définissables par rapport à
d'autres types de relations)
- sont les plus faciles à utiliser (avec leurs types de relations primaires
associées)
comme guide pour l'élicitation et la
modélisation de connaissances.
Tout type de concept que vous représentez doit spécialiser un des
types de concept en "caractères gras non italiques" de la page suivante.
Des types de relations associées à ces types de concept sont ensuite
donnés.
Les 2 pages qui suivent la page suivante propose une présentation plus
informelle de types de concepts de haut niveau.
Exercice à effectuer pendant la lecture de la page suivante :
- Pour au moins 3 sens du terme "représentation de connaissances", citez leurs
généralisations parmi les types de concepts de page suivante.
Note: en français ou en anglais, "représentation" a une dizaine de sens,
ceux évidents lorsque l'on rajoute les adjectifs
"théatrale", "syndicale", ...
en#"knowledge-representation"
.> (pm#knowledge-representation_process < pm#process)
(pm#knowledge-representation_content < pm#description)
(pm#knowledge-representation_character-string < pm#description_instrument)
(pm#knowledge-representation_physical-support < pm#physical_entity);
En FL (note : la section 0.o.meta (Résumé) donne une typologie complémentaire pour les types de 2nd-ordre) :
thing (^anything that exists or that can be thought about^) > partition { (situation (^"situ"; anything "occuring" in a real/imaginary region of time&space, aka. occurrent, perdurant, process, event^) > partition { state (^"stat"; situation that is not a process^) (process (^"proc"; situation "making a change"^) > (problem_solving_process (^e.g., software_lifecycle_process^) > KADS_generic_process (e.g., KADS_systematic_diagnosis^) ) (process_playing_a_role (e.g., consuming_process, creating_process^) > event (^"evnt"; process considered instantaneous from some viewpoint^) ) ) } situation_playing_a_role (^e.g., outcome, accomplishment^) ) (entity (^"enti"; thing that is not a situation -> that may "participate" to one, aka. endurant, i.e., "individual wholly present whenever it is present"^) > partition { (spatial_entity (^"spac", spatial substantial (existentially independent endurant) ^) > partition { (physical_entity (^"phys"^) > entity_that_can_be_or_was_alive) spatial_non-physical_entity (^"snpe"; e.g., geometry_object^) } spatial_object_playing_a_role (^e.g., place, physical_entity_part/substance^) ) (non-spatial_entity > partition { (non-spatial_entity_existentially_dependent_on_another_entity = ufo#Moment, > partition { (ufo#Intrisic_Moment > (ufo#Mode (^e.g.: John's desire, Intention, Perception, Symptom, Skill^) = characteristic_or_attribute_or_measure, > partition { characteristic (^"chrc"; e.g., color, wavelength^) attribute_or_measure (^"meas"; e.g., red, '620 to 740 nm'^) } (ufo#Externaly_Dependent_Mode part of: 1 Relator, ufo#externaly_dependent_on: 1..* Entity ) ) ) (ufo#Relator (^"rltr"; e.g., Marriage, Enrollment, Employment, Mandate^) part: 2..* ufo#Externaly_Dependent_Mode ) } ) (non-spatial_entity_existentially_independent = non-spatial_substantial, > partition { temporal_entity (^"time"; e.g., date, duration^) (non-spatial_non-temporal_substantial > partition { (description_content/instrument/support (^"desc"^) > description (^"dcon"; e.g., Type, proposition^) description_instrument (^"dins"; e.g., language^) description_support (^"dsup"; e.g., file^) ) non-spatial_non-temporal_non-chrc/meas/desc_substantial (^"nsto", e.g., justice^) } ) } ) } ) } entity_playing_a_role (^e.g., owner, agent^) ) } thing_playing_a_role (^e.g., creation, part^);
Top-level concept type specialization hierarchy (e.g., usable for
categorizing information, especially since at each level the "*1*" and the
"*2*" types form a partition; the other types are not exclusive with the first two).
Thing //anything 1sit. Situation //thing "occuring" in a (real or not) region of time/space 1sit.1proc. Process //thing making a change 1sit.1proc.1transf. Transformation //e.g., aggregation, removal 1sit.1proc.2ntransf. Non-transformation //e.g., move, selection/association 1sit.2stat. State //situation that is not a process 1sit.3role. Role_of_situation //partition only wrt same link 1sit.3role.1rSit. Role_of_situation_wrt_a_situation //e.g., Successor 1sit.3role.2rEnt. Role_of_situation_wrt_an_entity //e.g., Generator //e.g., Process_with_input_an_entity 2ent. Entity //thing "involved" in a situation 2ent.1spa. Spatial_entity 2ent.1spa.1phys. Physical_entity //e.g., Animal (e.g., Person) 2ent.1spa.2nphys. Non-physical_spatial-entity 2ent.2nspa. Non-spatial_entity 2ent.2nspa.attr. Attribute-or-Quality-or-Measure 2ent.2nspa.n-attr. Non-AttributeOrQualityOrMeasure_non-spatial_entity 2ent.3role. Role_of_entity //partition only wrt same link 2ent.3role.1rSit. Role_of_entity_wrt_a_situation 2ent.3role.1rSit.1descr. Situation_description_entity 2ent.3role.1rSit.2parti. Process_participant //or: Situation_non-description_entity 2ent.3role.1rSit.2parti.1in. Process_in-participant //e.g., Agent, Object, Parameter 2ent.3role.1rSit.2parti.2out. Process_out-participant //e.g., recipient, created_entity 2ent.3role.2rEnt. Role_of_entity_wrt_an_entity 3role. Role_of_thing //e.g., temporal role like a phase, such as // beginning_process/ending_process or, for a person, minor/adult 3role.1rSit. Role_of_thing_wrt_a_situation 3role.2rEnt. Role_of_thing_wrt_an_entity
À partir d'un processus (en FL ci-dessous, graphiquement page suivante) :
any process relation_from_process_to_spatial_entity : 0..* spatial_entity, relation_from_process_to_temporal_entity : 1..* temporal_entity, relation_from_process_to_event : 1..* event, relation_from_process_to_state : 1..* state, relation_from_process_to_process_attribute: 0..* process_attribute, relation_to_process_participant : 1..* participant, relation_to_another_process : 0..* process, relation_to_description : 0..* description; relation_from_process_to_spatial_entity > from_place place to_place via_places; relation_from_process_to_temporal_entity > since_time time duration until_time; relation_from_process_to_event > triggering_event ending_event; relation_from_process_to_state > (predecessor_state > beginning_state precondition cause) (successor_state > end_state postcondition consequence purpose); relation_from_process_to_process_attribute > manner speed; relation_to_process_participant > (relation_to_used_object alias: object, > input object parameter material instrument) (relation_to_participating_agent > agent initiator) (relation_to_created-or-modified_participant > (relation_to_created-or-modified_object > input-output_object generated_object deleted_object) (relation_to_modified_agent > patient experiencer recipient) ); relation_to_another_process > specializing_process generalizing_process sub-process method embedding_process; relation_to_description //useful for annotating but not for modelling knowledge/software > description;
Note. Il y a de nombreuses manières de formaliser des contraintes sur
l'ordre d'exécution
de différent processus. Ces différentes
manières pourraient être représentées via des
spécialisations des types de relations 'predecessor_state' et 'successor_state'.
- Le langage des "réseaux de Petri" [Petri net]
est un des formalismes les plus expressifs
(lire la page pointée).
Il étend le langage des automates d'états finis.
- D'autres modèles permettant de représenter le parrallélisme|concurrence entre
processus sont : [process algebra],
[actor model] et
[trace theory].
------------------------0..*--> |______________________________ spatial_entity temporal_entity <--1..*--------------------------- (relation_to_another_spatial_entity) ^ ^ | \0..* 1..*/ | \ / | (relation_from_process_to_spatial_entity \ /(relation_from_process_to_temporal_entity | > from_place place \ / > since_time time duration to_place via_places) \ / until_time) | \ / | \ / (relation_from_state_to_temporal_entity)| ---0..*--> process_attribute \ / | |____________________________________________ | | --------------------------------1..*--> event | (relation_from_process_to_process_attribute \ | | /(relation_from_process_to_event | > manner speed) \ | | / > triggering_event ending_event) | \ | | / | \| |/ | 1..* state <--------------------------------- process ---------------------------------------> 1..* state | (predecessor_state / | | \ (successor_state | | > beginning_state / | | \ > end_state postcondition | | precondition cause) / | | \ consequence purpose) | |(part) | | | | (part)| | | | | | | | (relation_to_process_participant | | | |(relation_to_created-or-modified_participant | | > (relation_to_used_object | | | | > (relation_to_created-or-modified_object | | alias: object, | | | | > input-output_object generated_object | | > input_object parameter | | | | deleted_object) | | material instrument) | | | | (relation_to_modified_agent | | (relation_to_participating_agent| | | | > patient experiencer recipient) ) | | > agent initiator) ) | | | | | v v | | v v 1..* state <----------------- 1..* participant | | 0..* participant -----------------------> 1..* state (state) / \ (state) / \ (relation_to_description / \(relation_to_another_process > description) / \ > specializing_process generalizing_process | | sub-process method embedding_process) | | 0..*| |0..* ---------------------------0..*--> v v |_________________________________ description process (relation_to_another_description | | \ > generalizing-description | | \ sub-description correction) | | ------------------------0..*--> description_medium | | (description_medium) | | agent <--1..*--------------------------/ \----------------------------0..*--> description_container (description_believer) (description_container)
Exercice :
1. Représentez en FL la phrase suivante en vous aidant des types de relations de la page
précédente.
"The content of the sentence '2% of men that travel from Chicago to Boston from 14:00 to 16:00
on a Friday, gnaw all their nails' can be described by this sentence".
2. Il manque d'importantes relations à cette représentation de connaissance pour qu'elle soit
précise/vraie/utile. Lesquelles ?
//2. This sentence is likely to be false if more details are not given, e.g.,
// precisions about when the referred travels occured, on which airline, ...
//1. In FL:
[2% ^(man agent of: (a travel from_place: Chicago, to_place: Boston,
since_time: 14:00, until_time: 16:00, time: a Friday) ) ?m
agent of: (a gnawing object: every ^(nail part of: ?m))
] description: "2% of men that travel from Chicago to Boston from 14:00 to 16:00
on a Friday, gnaw all their nails";
//1. In FL-DF:
--------------------------------------------------------------------------------------
| man --agent of _[2% ^m ^-> a ^t]--> travel --from_place _[any ^t ^-> .]--> Chicago |
| | |--to_place _[^t ^-> .]--> Boston |
| | |--since_time _[^t ^-> .]--> 14:00 |
| | |--until_time _[^t ^-> .]--> 16:00 |
| | |--time _[^t ^-> a]--> Friday |
| |--agent of _[^m -> a ?g]--> gnawing --object _[?g -> every ?n]--- |
| |--part _[^m <- ?n]--------> nail <------------------------------| |
--------------------------------------------------------------------------------------
|
|--description _[. -> .]--> "2% of men that travel from Chicago to Boston from 14:00 to 16:00
on a Friday, gnaw all their nails" // "_[. -> .]" is optional
//1. One alternative way in FL-DF:
man --agent of _[= ?d1, 2% ^m ^-> a ^t, //"= ?d1" (or "?d1"): reference for this relation
| ]--> travel --from_place _[?d2, any ^t ^-> .]--> Chicago
| |--to_place _[?d3, ^t ^-> .]--> Boston
| |--since_time _[?d4, ^t ^-> .]--> 14:00
| |--until_time _[?d5, ^t ^-> .]--> 16:00
| |--time _[?d6, ^t ^-> a]--> Friday
|--agent of _[?d8, ^m -> a ?g]--> gnawing --object _[?d7, ?g -> every ?n]---
|--part _[?d9, ^m <- ?n]---------> nail <------------------------------------|
{a description ?d1, a description ?d2, a description ?d3, a description ?d4, a description ?d5,
a description ?d6, a description ?d7, a description ?d8, a description ?d9
} --part of _[distr . -> a ?d]--> description --description of _[. -> a ?s]--> situation
^
"2% of men that travel from Chicago to Boston |
from 14:00 to 16:00 on a Friday, gnaw all their nails" --description of _[. -> ?s]---|
Exercice :
- Catégorisez des types de relations pouvent répondre aux questions
"who/what/why/where/when/how". Utiliser 'wh-/how_relation' pour identifier
leur plus proche supertype commun. Qu'en déduisez-vous concernant l'utilisation
des "wh-/how relations" pour l'élicitation, la catégorisation, et la
normalisation des connaissances (-> leur comparabilité et donc leur exploitabilité) ?
wh-/how_relation _(*) (^this type permits to categorize relations based on
who/what/why/where/when/how questions; this is a subjective and ineffective
way of categorizing relations;
since the meaning of these questions are subjective and not normalizing,
they should not be used for knowledge elicitation^)
> how_relation
who_relation what_relation why_relation where_relation when_relation;
how_relation
> instrument method sub_process
(how_much_relation
> duration relation_to_attribute_or_quality_or_measure
relation_from_collection_to_number);
who_relation (^e.g., agent initiator, patient, experiencer, recipient^)
> relation_to_participating_agent relation_to_modified_agent
owner generator creator; //for normalization purposes, do not use
//these last three types nor relations from agent to process
what_relation
> object/result process_attribute mereological_relation method
relation_from_collection relation_to_collection contextualizing_relation;
why_relation (^e.g., cause, method, goal, triggering_event, ...^)
> relation_from_process_to_state relation_from_process_to_event;
//for normalization purposes, do not use relations to process
where_relation (^e.g., where, from/to where, ...^)
> relation_to_spatial_entity part_of member_of;
//for normalization purposes, do not use '...-of' relations
when_relation
> relation_to_temporal_entity
Process type [give an identifier (e.g., wn#travel) or an informal name (e.g., "travel")]:
Where does it occur [e.g., in FL, `from:wn#Paris, to:"Berlin", via: ["Strasbourg", "Bohn"]´]:
When does it occur [e.g., `from:1/1/2001, to:31/12/2001,
frequency: "every 2nd Tuesday of the month", duration: 8 wn#hour´]:
After/before which process(es) does it occur [e.g., `triggering_event: wn#full_moon´]:
After/before which state(s) does it occur [e.g., `precondition: "John is at Paris"´]:
Who does/experiences/... it [e.g., `agent: JohnDoe.info, experiencer: JohnDoe.info´]:
What does it use/generate/... [e.g., `material: "100 kg of fuel", tool: a wn#train´]:
Which (direct) subprocesses does it involve [e.g., `subprocess: pm#train_changing´]:
Where is it described [e.g., `description: ThomsonSalesmanTravelsToBerlin.info´]:
Type/propriété essentiel(le)
(alias, toujours nécessaire) pour un objet (type ou individu):
l'objet doit avoir cette propriété (i.e., doit avoir le type
représentant cette propriété) dans tous les
"mondes possibles (imaginables)".
<- notions de "monde" et de "nécessité" de la logique du second-ordre;
<- notion de "définition" dans les langages dont l'expressivité est
inférieure à la logique du 2nd-ordre.
E.g., la propriété "avoir un cerveau" peut être vue (définie) comme
essentielle pour tout mammifère vivant:
"every mammal must have a brain in every possible world" ou
`any mammal necessarily has a brain´.
La propriété "être dur" ne peut être essentielle pour les éponges
car une éponge peut devenir molle.
Type/propriété rigide [+R property/type]:
propriété essentielle à toutes les instances possibles de cette
propriété
(en d'autres termes, toute instance de cette propriété a nécessairement cette
propriété), i.e.,
p est rigide <=> nécessairement, si p est toujours vrai dans un monde
alors p est vrai dans tous les mondes.
Formellement: rigide(p) <=> (□ ∀x ( p(x) => □ p(x) ) )
E.g. "avoir un cerveau" n'est pas une propriété rigide car il est possible
d'imaginer que des objets qui ont un cerveau dans notre monde n'en aient pas dans un
monde imaginaire. Par contre, "être ou avoir été un mammifère" ou
"avoir des mammelles pour une mammifère femelle" sont des propriétés
rigides.
Type/propriété semi-rigide
[-R property/type]:
propriété pouvant être essentielle pour certains objets et
pas pour d'autres.
E.g., "avoir un cerveau" est une propriété semi-rigide car certains
(types d')objets doivent en avoir et d'autres non.
Type/propriété anti-rigide [~R property]: propriété
jamais essentielle.
Un type anti-rigide ne peut généraliser que des types anti-rigides.
E.g., une ontologie ne peut spécifier que le type "étudiant" généralise
le type "personne" si l'auteur de ce dernier type considère que "être une personne"
est une propriété rigide.
Ces notions sont recommendées entre autres par Ontoclean (une méthodologie pour créer/analyser des ontologies): afin de préciser le sens d'un type et d'éviter certaines erreurs de modélisation, tout type devrait être spécifié (directement ou non) comme instance de ontoclean#rigid_type (R), ontoclean#not-rigid (-R) ou ontoclean#anti-rigid_type (~R)
Exercice de contrôle
- un type anti-rigide est-il aussi semi/non-rigide ?
- pour chacun des types suivants, indiquez ceux qui sont non-rigides ou anti-rigides :
thing, place, country,
group, social_entity, amount_of_matter,
physical_object, currently_or_previously_living_thing, animal, vertebrate, person, fruit,
apple,
red_thing, red_apple, agent, legal_agent, food, butterfly,
caterpillar.
1) Oui 2) -R: red_thing, ~R: red_apple, agent, legal_agent, food, caterpillar, butterfly
Type/propriété (d'un objet) suppléant un
critère d'identification
[(+I) +O(wned by an objet) property/type]:
propriété fournissant un critère suffisant pour distinguer l'objet
(à qui appartient cette propriété) d'un autre objet
(critère nécessairement commun à 2 objets identiques,
e.g., un même objet à différentes dates).
L'expression "suppléant un critère" veut dire qu'un tel critère n'est pas
hérité d'une généralisation de cette propriété: il
n'appartient qu'à cette propriété et à ses spécialisations.
Exemple: peut-on avoir les relations suivantes ?
time_duration
example: "60 minutes" "1 hour", //identical objects
> (interval_of_points_in_time
example: "13:00-14:00, on the 13/08/2012"
"13:00-14:00, on the 17/03/2008");
La relation '>' ci-dessus est impossible car des intervals de points dans le temps sont
toujours différents même s'ils ont la même durée, alors que deux
durées peuvent être identiques.
En d'autres termes, un interval de points dans le temps n'est pas une durée,
il a une durée.
Plus précisément, deux intervals de temps sont les mêmes si et
seulement si ils ont les mêmes parties.
Ce critère est connu sous le nom de "extensionalité méréologique".
Il s'applique à toutes les choses qui peuvent être vues comme la somme de leurs parties.
Le type "interval_of_points_in_time" est donc +O, comme l'est le type "amount of matter".
En effet, une "quantité-portion de matière" réfère à par exemple
à 5 litres particuliers d'eau ou 3,5 kilogrammes particuliers d'argile.
Ces litres/kilogrammes particuliers ne réfèrent pas à une substance ("eau",
"argile"), ni à un volume ou un poids.
Même si le critère d'identification est difficile à définir, le fait de
noter que deux objets ont des "propriétés essentielles" différentes
(et donc des critères d'identification différents même si non définis)
permet de les différencier. E.g., pour une "statue d'argile", sa forme est une
"propriété essentielle" mais pour la "quantité-portion d'argile" qui compose
cette statue cette forme n'est pas une "propriété essentielle" (la même
portion d'argile peut être ré-utilisée pour une autre statue).
Ces deux types objets sont donc différents. Ils doivent donc être
distingués dans une ontologie et lors d'une représentation de connaissances.
Type/propriété (d'un objet) "portant un critère d'identification"
[+I-O (or, simply, +I) property/type]:
comme ci-dessus sauf que le critère est hérité d'une généralisation
de cette propriété.
Type/propriété (d'un objet) ne portant pas de critère d'identification [-I(dentifying) property/type].
Dans diverses méthodologies (dont OntoClean), les types +O ou +I sont appelés
"sortals".
Un sortal ne peut généraliser que des sortals
et son critère est hérité par ces sortals.
Tout individu devrait être instance d'au moins un sortal. Ceci rejoint le
motto de Quine: "No entity without identity" [Quine, 1969].
Si une chose est instance de différents types, ceux-ci doivent être
généralisés par un type portant un critère d'identification
pour cette chose.
Ainsi, toute chose doit instancier un unique "type plus général" portant son
critère d'identification.
Dans les ontologies dites 3D, chaque (type d')objet est associé à un point dans
le temps, afin de ne pas avoir à associer des "types (et critères d'identification)
exclusifs" à un même objet qui évolue dans le temps
(e.g., le type "student" puis le type "non-student", ou encore le type
"caterpillar" puis le type "butterfly").
Dans les autres ontologies, il faut utiliser des contextes pour gérer ces cas
ou créer des objets 3D.
Exemple de modélisation incorrecte détectée via de telles notions,
suivie d'une correction.
 |
 |
Exercice de contrôle
- un type +O est-il aussi +I+O si "+I" n'est pas l'abréviation de +I-O ?
- un type +O est-il aussi "+I" si "+I" est l'abréviation de +I-O ?
- donner au moins un critère d'identification pour distinguer deux triangles.
- pour chacun des types suivants, indiquez s'il est +O, +I ou -I :
thing, amount_of_matter, place, country, geographical_region,
group, group of people, social_entity, organization,
physical_object, living_thing, animal, lepidopteran, vertebrate, person, fruit, apple,
red_thing, red_apple, agent, legal_agent, food, caterpillar, butterfly.
- oui
- non
- taille de chacun des 3 cotés de chaque triangle
- +O: amount_of_matter, place, country, physical_object, living_thing,
animal, lepidopteran, fruit, apple, organization, group, person
+I-O: food, red_apple, vertebrate, group of people,
legal_agent, geographical_region, caterpillar, butterfly
-I: thing, agent, red_thing, social_entity
Critère d'unité (CU) d'un objet: une ou plusieurs "relations d'unification"
exprimant ce qui relie les sous-parties de l'objet, et permettant donc de savoir
- pourquoi l'objet est un "tout" [whole] plutôt qu'une somme arbitraire de choses, et
- ce qui ne peut faire partie de l'objet.
Il y a différentes sortes de "tout" (et donc de relations d'unification), e.g.,
"topologique" (morceau de charbon, ...), "morphologique" (constellation, ...) et
"fonctionnel" (marteau, bikini, ...).
Type/propriété unifiant homogène [+U property/type]: dont toutes les instances portent un même CU, que celui-ci soit connu ou pas. Exemple de types +U: ocean
Type/propriété unifiant hétérogène [-U property/type]: dont toutes les instances portent un CU (et sont donc chacune un "tout") mais pas nécessairement le même. Un exemple d'un tel type est "legal_agent" si à la fois des personnes et des companies (avec différent CUs) peuvent être de ce type.
Type/propriété non-unifiant [~U property/type]: dont au moins une instance ne porte pas de CU. E.g., "amount_of_matter" et "amount_of_water" puisque leurs instances ne sont pas nécessairement des touts (rien ne permet de "reconnaitre" une sous-partie de ces instances; toute sous-partie d'une instance d'un de ces types est d'ailleurs aussi une instance de ce type).
L'UC d'un type doit être hérité par ses spécialisations.
Un type ~U ne peut avoir que des types ~U pour spécialisations.
Les charactéristiques +U et ~U (mais pas -U) sont donc héritées dans la
hiérarchie de spécialisation.
Exercice de contrôle
- un type ~U est-il aussi -U ?
- pour chacun des types suivants, indiquez s'il est +U, -U ou ~U :
thing, amount_of_matter, place, country, geographical_region,
group, group of people, social_entity, organization,
physical_object, living_thing, animal, lepidopteran, vertebrate, person, fruit, apple,
red_thing, red_apple, agent, legal_agent, food, caterpillar, butterfly.
1) non
2) +U: country, social_entity, organization, physical_object,
living_thing, animal, vertebrate, person, lepidopteran, caterpillar, butterfly,
fruit, apple, red_apple
-U: thing, place, agent, legal_agent, geographical_region, red_thing
~U: amount_of_matter, food, group, group of people
Type/propriété non-dépendant [-D property]: dont l'existence d'au moins une de ses instances n'implique pas l'existence d'une autre chose.
Type/propriété dépendant [+D property]:
chacune de ses instances implique l'existence d'une autre chose.
Ce(tte) propriété/type est non-rigide.
La charactéristique +D (mais pas -D) est héritée dans la
hiérarchie de spécialisation.
Type/propriété spécifique constamment dépendant: chacune de ses instances implique l'existence d'un objet particulier, différent pour chaque instance, e.g., l'existence d'une personne est "dépendante" de son cerveau.
Type/propriété générique constamment dépendant: chacune de ses instances implique l'existence d'un objet, e.g., l'existence d'un élève dépend de l'existence d'un enseignant.
Attribution: type de choses qui, tel "red_thing", ont un
certain attribut (e.g., couleur, poids, ...) avec un certain type de
valeur (e.g., rouge, rouge clair, 28 à 34 kg, ...).
Les attributions dépendent des attributs. Ils ont peu de contraintes associées et
sont difficiles à classer sans répéter le classement de ces attributs et/ou
de leurs valeurs.
Il vaut donc mieux associer directement des attributs à des individus et ainsi éviter
de définir des attributions.
[Phased sortal]: type anti-rigide dont les instances peuvent changer de
"critère d'identification" (et donc de type) au cours de leur existence,
e.g., le type "student" puis le type "non-student",
ou encore le type "caterpillar" puis le type "butterfly".
Comme tout sortal doit être instance d'au moins un type de sortal, le terme "lepidopteran" doit
être utilisé pour généraliser "caterpillar" et "butterfly".
De manière similaire, un "pays" (au sens géo-politique) peut disparaitre
(il est dépendant d'un contexte politique)
sans que la région géographique de ce pays ne disparaisse (celui-ci n'est pas
dépendant d'une autre entité: il n'a pas de critère d'unité).
Les deux notions sont donc à distinguer.

Rôle: type charactérisant la manière dont une chose peut participer à une situation (état ou processus) et donc être dépendant de cette situation (e.g., de nombreux sortals peuvent être vues comme "nourriture" et donc être aussi classés en fonction de ce rôle). Comme il s'agit d'une participation "possible" et non systématique, ce type est anti-rigide, et donc ne peut généraliser un type rigide. E.g., "animal" ne peut spécialiser "agent" (d'un processus): un animal n'est pas un agent, il "peut" être un agent. De même, "legal_agent" ne peut généraliser "person" et "organisation". Un rôle n'a pas de critère d'identification associé.
Exemple de modélisation incorrecte détectée via de telles notions,
suivie d'une correction.
 |
 |
Exercice de contrôle
- parmi les types suivants, indiquez ceux qui sont +D :
thing, amount_of_matter, place, country, geographical_region,
group, group of people, social_entity, organization,
physical_object, living_thing, animal, lepidopteran, vertebrate, person, fruit, apple,
red_thing, red_apple, agent, legal_agent, food, caterpillar, butterfly.
Solutions: +D: country, person, agent, legal_agent, food Pour les autres types, voyez l'ontologie ci-dessous qui est indexée avec les diverses méta-propriétés jusqu'ici présentées (cliquez sur la figure pour une explication détaillée).
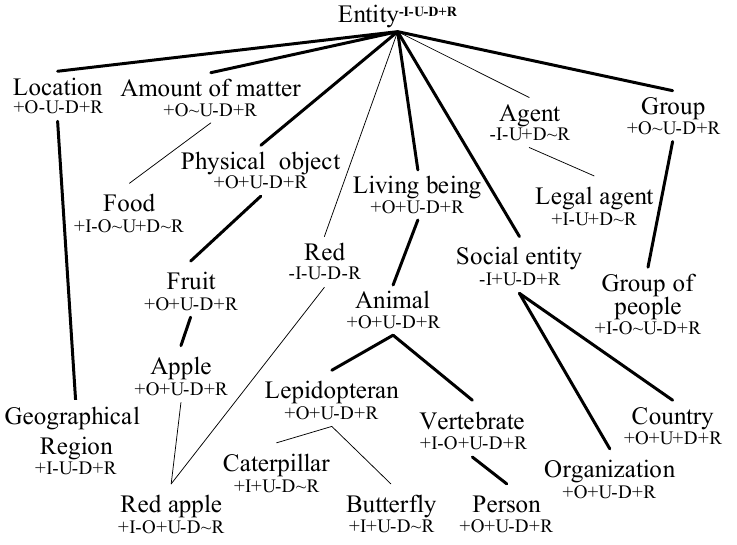
[Mixin/dispersive types]: types ayant différent critères d'identité.
Résumé des types [universals]
d'entités-qui-ne-sont-pas-des-attributs [Substantial universals]
proposés par OntoUML, un langage de modélisation
d'ontologies
(pour une explication détaillée, cliquez sur la figure et allez à la page
numérotée "106" dans le document téléchargé (page 129 de ce PDF).
Résumé des contraintes associées à ces types
| Exemple de sous-types
|
Résumé des types de second-ordre [universals] pour des entités (endurants)
(pour une explication détaillée, cliquez sur la figure et lisez la section 2.2)
:
//In FL and reusing the terms introduced in the 0.o.tc Section (note: in the UFO/OntoUML methodology, // any type should be categorized as instance of 1 of those in bold below, yellow above) : ufo#Universal = Type, //2nd order type > partition { (ufo#Perdurant_Universal = Situation_type) //not in the above figure (ufo#Endurant_Universal = Entity_type, //any individual (i:): wholly present when present > partition { (ufo#Moment_Universal //i: inheres-in (existentially-depend-on) an Endurant > partition //e.g.: a person's headache, a covalent bond between atoms { (ufo#Intrisic_Moment_Universal //i: inheres in *1* indiv, e.g., Apple's color > (ufo#Mode_Universal //e.g.: John's desire, Intention, Perception, = Characteristic-or-attribute-or-measure_type, // Symptom, Skill > ufo#Externaly_Dependent_Mode_Universal //i: part of a Relator and ) ) // externaly dependent on an Endurant ufo#Relator_Universal //i: mediates 2..* Endurant, composed of } ) // 2..* Externaly_Dependent_Mode, e.g., Marriage, Service agreement, // Enrollment, Employment, Presidential mandate (ufo#Substantial_Universal //i: existentially-independent Endurant > partition { (ufo#Sortal_Universal > partition //+I (ou +I+O) { (ufo#Rigid_Sortal > partition //i: if exists, necessarily so { (ufo#Sustance_Sortal > excl { ufo#Kind //+I for unique instance, e.g., Person //parts are distinct, e.g., "CPU functional_part of: a computer" ufo#Collective //parts not distinguished, e.g., Forest } ) ufo#SubKind //e.g.: Man < Person (+I supplied by Person) } ) (ufo#AntiRigid_Sortal > partition //e.g.: Student, Husband { ufo#Phase //relationally independent, e.g., Child < Person ufo#Role //relationally dependent, e.g., Student < Person } ) // Student mediator/relator: Enrollment } ) (ufo#Mixin_Universal > partition //aggregates properties of distinct Sortals { (ufo#Rigid_Mixin //e.g., Work_of_Art, People, Organization, Law > ufo#Category //rigid and relationally independent ) //e.g., Furniture > Table Chair; Physical_Object (ufo#NonRigid_Mixin //e.g., Insurable, Contract ? > (ufo#NonRigid_Mixin > ufo#RoleMixin //e.g., Customer > Individual_C Corporate_C ) ) } ) } ) } ) };
Il y a différentes sortes de relations méréologiques, i.e., "partie de",
e.g., subprocess, temporal_part, spatial_part, physical_part, matter, etc.
Il y a aussi différentes théories méréologiques.
La figure ci-dessous donne une typologie. Chaque flèche va d'une théorie
à une théorie plus forte.
Cliquez sur la figure et allez à la page numérotée "144" dans le document
téléchargé (page 167 de ce PDF) afin de lire les axiomes de la théorie
la plus faible/simple.
Certaines "choses", comme par exemple les concepts mathématiques, peuvent être entièrement définies. Certaines autres, comme les démonstrations mathématiques peuvent être entièrement représentées. Toutefois, la plupart des choses naturelles/physiques ne peuvent être que "partiellement définies" (avec des conditions nécessaires ou suffisantes) ou partiellement décrites (avec des "croyances" qui ne sont alors que des "interprétations" ou des "modèles").
Il est commun, par emphase ou pour des raisons de facilité, de "sur-généraliser" ou de "sur-spécialiser" ses phrases et donc de les rendre fausses ou moins utiles qu'elles le seraient si ces phrases étaient plus précises. Plus une phrase est précise (sans être sur-spécialisée), plus elle a de chances d'être utile et d'être acceptée par d'autres. Voici donc quelques exemples de "bonnes pratiques pour la représentation des connaissances".
u2#study_of_Dr_Doolittle_in_2002#` `every (wn#daylight ?t pm#part of: from 5/10/2001 to 2/12/2002) `every wn#carinate_bird can be pm#agent of a wn#flight with pm#time ?t´ ´ with pm#place wn#France´.
Être précis implique l'utilisation d'un langage ayant une bonne expressivité, au moins celle de "la logique du premier ordre avec des contextes et des quantificateurs numériques". Durant une phase de modélisation des connaissances à des fins de partage des connaissances, la représentation des connaissances ne doit pas être volontairement restreinte ou biaisée pour convenir à une application particulière ou un type particulier d'applications. Ainsi la BC est réutilisable pour d'autres types d'applications. Suivant les contraintes qu'ils ont, les développeurs d'applications peuvent alors choisir et adapter différents types de connaissances à partir de modules réutilisables.
"Plus organisé" signifie: plus de relations (directes ou indirectes) entre les objets de la BC. Plus organisé implique plus précis. Un moyen partiel mais efficace d'organiser une BC est d'intégrer sans perte des ontologies de haut niveau (plus des ontologies sont intégrées, mieux c'est) et d'encourager/conduire les utilisateurs à utiliser (et donc spécialiser ou instancier) les types de concepts et de relations de haut niveau (plus ils sont utilisés, mieux c'est).
Les types de relations les plus communément utilisés à des fins d'inférence sont ceux d'identité, d'exclusion (négation, inverse, complément, ...), de généralisation (implication-logique, super-type, instance-de, terme-plus-général,. ..), de sous-partie (sous-processus, substance, partie-physique, ...) et d'autres relations transitives (membre-de, ...).
S'il y a un choix à faire entre deux sortes de relations
pour représenter quelque chose, et que une seule des deux est transitive,
cette dernière doit généralement être choisie.
En effet, dans un ordre partiel, un objet a une place unique, ce qui évite
des redondances et facilite la comparaison des connaissances (et donc aussi les
inférences et recherches de connaissances).
Tous les objets de la BC devraient avoir une place (unique) dans au moins sa
hiérarchie de généralisation.
Ce n'est pas possible en utilisant seulement des relations de
généralisation classiques (sous-type-de, instance-de,
implication-logique) lorsque la BC qui des objets informels et des
phrases (semi-)formelles expressives.
Une relation de "généralisation générique"
(ici notée ".>") est donc utile.
La classique relation "sous-type" est notée ">".
Voici un exemple d'utilisation de ".>" et de ">"
dans la notation FL.
"animal related concept" // "...": informal object .> ("animal right" .> (right_of_any_animal :<=> (right owner=> any animal), // ":<=>" full definition instance: (right_of_Garfield .> right_of_Garfield_in_2010), //specialization of an individual > (right_of_every_animal_in_2010 owner=> every animal, > (right_of_Garfield_in_2010 owner=> Garfield))));
Toujours pour éviter les redondances et faciliter la comparaison des connaissances, dans les noeuds relation il est préférable de n'utiliser que des types de relations basiques et binaires. Toutefois, si le langage utilisé le permet, il est acceptable d'utiliser des types de concept dans les noeud relation. Ceci permet d'éviter de déclarer des types de relations et donc de dupliquer des parties de la hiérarchie de types de concept. E.g., dans l'expression FE `a car with wn#color a wn#red´, wn#color est un type de concept.
Les relations d'argumentation (preuve, objection, argument, exemple ...) ne sont généralement pas transitives et ont donc tendance à conduire à des structures "spaghetti" qui aident peu la recherche des connaissances et les inférences. Les relations d'argumentation ne doivent être utilisées que lorsque ce qui doit être représenté ne peut l'être (au moins partiellement) d'une manière plus précise et organisée, typiquement via des relations de spécialisation ou de sous-processus. Si cela est nécessaire, des relations d'argumentation peuvent alors être utilisées dans le contexte externe de ces relations de spécialisation ou de sous-processus.
Pour les mêmes raisons et également pour normaliser les structures d'argumentation, au lieu d'utiliser des relations de type pm#objection, il vaut mieux utiliser des relations de type pm#corrective_specialization ou pm#corrective_generalization, avec des relations de type pm#argument dans leurs contextes externes. Ainsi, l'objection est indirectement affirmée et en plus une correction est donnée via une relation transitive et un argument est donné pour cette correction. Cette correction et cet argument vont faciliter l'acceptation de l'objection et peuvent être eux-mêmes des noeuds source de relations de correction.
Exemple de "discussion structurées" (structure d'argumentation multi-sources) dans la notation FL.
"knowledge_sharing_with_an_XML-based_language is advantageous" .< ("knowledge_sharing_with_an_XML-based_language is possible" .< knowledge_sharing_with_an_XML-based_language __[pm] ) __[pm], argument: – "XML is a standard" __[pm] – ("knowledge_management_with_classic_XML_tools is possible" corrective_specialization: "structural_knowledge_management_with_classic_XML_tools is possible" __[pm, argument: "classic XML tools only manage structures, not semantics" __[pm] ] ) __[pm], argument: "the use of URIs and Unicode is possible in XML" __[fg, objection: "the use of URIs and Unicode can easily be made possible in most syntaxes" __[pm#tbl#] ], objection: – ("the use_of_XML_by_KBSs implies several tasks to manage" argument: "the internal_model_of_KBSs is rarely XML" __[pm] ) __[pm] – ` "an increase of the number of tasks ?t to_manage" has for consequence "an increase of the difficulty to develop software to manage ?t" ´ __[pm], objection: – "knowledge_sharing_with_an_XML-based_language will force many persons (developers, specialists, etc.) to learn how to understand complex_XML-based_knowledge_representations" __[pm] – ("understanding complex_XML-based_knowledge_representations is difficult" argument: "XML is verbose" __[pm] ) __[pm];
Conflit (sémantique) implicite entre deux phrases affirmées: incohérence ou redondance partielle/complète entre ces phrases, qui n'a pas été rendue explicite via une relation de "correction". Pour comparaison, voici deux exemples de conflits explicites (et donc résolus) entre deux croyances:
u2#` u1#`every bird is agent of a flight´ has for pm#corrective_specialization u2#`most healthy flying_bird are able to be agent of a flight´ ´. u2#` u1#`every bird can be agent of a flight´ has for pm#corrective_generalization u2#`75% of bird can be agent of a flight´ ´.
Les conflits entre des définitions provenant de différentes sources n'indiquent pas qu'une des définitions est meilleure que l'autre (car les définitions ne sont ni vraies ni fausses) mais indiquent qu'une des sources (i.e., un des auteurs de ces définitions) a mal compris la signification d'un terme défini par une autre source et donc que ces sources parlent de choses différentes et qu'elles devraient utiliser des termes formells différents.
"Protocole de coopération" minimal de haut niveau pour l'ajout/fusion sans-perte d'une phrase affirmée, créée par un utilisateur U1, dans une BC:
Un protocole minimal similaire peut être utilisé pour la suppression sans perte d'une d'une phrase affirmée. Les termes peuvent être ajoutés ou supprimés via l'ajout ou la suppression de phrases affirmées.
Si deux BCs sont développées plutôt indépendamment ou si une fusion de deux BC est une nouvelle BC "indépendante" (i.e., dont les objets ne sont pas reliés à ceux deux premières BCs), les objets des BCs sont mutuellement peu reliés entre eux et il y a des "conflits" implicites entre eux. Il est difficile de résoudre ces conflits et de relier ces objets entre eux, que ce soit manuellement ou automatiquement. Il est donc difficile 1) de rechercher, fusionner/aligner et exploiter ensemble les contenus des BCs, ou 2) de faire en sorte que des outils ou des groupes utilisant ces KBs travaillent ensemble.
La plupart des outils (semi-)automatiques liés au Web sémantique sont destinés à atténuer la difficulté de recherche, comparer et fusionner des ontologies développées (semi-)indépendamment. Ces outils sont utiles, mais ils n'intègrent pas leurs résultats dans une BC partagée: leurs sorties sont des nouveaux fichiers/BCs formels dont les objets ne sont pas liés (explicitement, via des relations sémantiques) aux objets des autres BCs (ou de nombreuses autres BCs) sur le Web, en particulier les BCs sources. Ainsi, dans un sens, ces outils contribuent au problème qu'ils atténuent partiellement. En outre, comme les fusions qu'ils effectuent ne sont pas "sans perte", les mises à jour faites ultérieurement sur les fichiers/BCs que ces outils créent ne peuvent facilement être utilisés pour mettre à jour les BCs sources.
La plupart des outils manuels liés au Web sémantique sont des éditeurs de BC privés (qui conduisent donc leurs utilisateurs à créer des BCs plutôt indépendantes entre elles) ou bien des serveurs/éditeurs de BC partagés (e.g., Ontolingua, OntoWeb, Ontosaurus, Freebase et les serveurs wiki sémantique) qui n'ont pas de protocole de coopération entrainant une intégration des connaissances "sans perte d'informations". Par conséquent, ces outils
Le protocole minimal de coopération décrit précédemment
permet aux utilisateurs de créer une BC de manière coopérative
sans avoir à s'accorder sur une terminologie ou des croyances.
Ce protocole est déclenché pour chaque changement dans la base et
doit donc s'appuyer sur un SGBC pour détecter les conflits implicites.
Toutefois, une approche similaire peut être utilisée - bien que de
manière plus asynchrone - chaque fois que des personnes détectent
des conflits implicites dans la BC. Ainsi, une telle approche peut également
être appliquée sur des BC semi-formelles.
Par conséquent, cette approche pourrait être utilisée dans des
wikis sémantiques afin de résoudre leurs nombreux problèmes (dont
leurs problèmes de gouvernance) causés par leur manque de structure.
Beaucoup outils du Web 2.0 permettent aux gens d'associer des commentaires à des ressources entières (documents/KBs/services) et de les évaluer en fonction d'un critère (ou de quelques critères) tels que "utilité", "étendue du domaine couvert" et "véracité ". Ces outils permettent aussi souvent de voter sur les annotations et/ou les ressources. Via des statistiques sur les annotations et les votes, ces outils génèrent des "recommandations" et permettent ainsi de la recherche/synthèse collaborative d'informations (également appelée "recherche sociale/concurrente").
Cependant, la sémantique et l'utilité d'une approche aussi grossière (dans les ressources qu'elle indexe) est limitée et limitante. Voici quelques raisons:
Pour éviter cela, un logiciel aidant réellement la
coopération devrait
Question: comment mesurer la confiance à accorder à un phrase ou à
une personne/source,
comment construire cette mesure collaborativement (i.e.,
comment les utilisateurs d'une BC peuvent-il construire collaborativement une
représentation de la réputation
d'une personne ou d'une phrase) ?
Voici un exemple de modèle de base pour une mesure par défaut destinée à évaluer "l'utilité d'une croyance".
Ce modèle ne précise pas les fonctions à utiliser pour les combinaisons et les pondérations. Le choix d'une fonction particulière est quelque peu arbitraire. Chaque utilisateur devrait donc connaître ces fonctions et devrait être autorisé à créer ses propres fonctions pour satisfaire ses buts ou ses préférences.
Les résultats des "mesures par défaut" doivent être utilisés par des méthodes de "présentation par défaut". E.g., les phrases ayant une très faible valeur d'utilité peut être par défaut affichées avec une police très petite.
Ainsi, les mesures par défaut prenant en compte au moins les
éléments cités ci-dessus devraient inciter les fournisseurs
d'informations à
- être prudent et précis dans leurs contributions, et
- à donner des arguments pour ces contributions.
En effet, contrairement à des discussions traditionnelles ou à des
commentaires anonymes, ici des phrases non réfléchies vont avoir une
influence sur les mesures d'utilité d'un auteur et donc sa réputation.
Cela peut conduire les utilisateurs à ne pas écrire des phrases en
dehors de son domaine d'expertise ou sans préalablement faire de
vérifications. Par exemple, quand une croyance d'un utilisateur est
contredite par un autre utilisateur, l'utilité de son auteur décroit
et il est ainsi incité à approfondir la structure argumentation sur
sa croyance ou à ôter cette croyance de la BC.
Avec le modèle ci-dessus, utiliser un nouveau pseudo lorsque l'on écrit n'importe quoi (diffamations, phrases non réfléchies/vérifiées, ...) mais aucune valeur d'utilité n'est associé à ce nouveau pseudo (et cette valeur pourra même devenir négative si d'autres utilisateurs repèrent la faible qualité des informations fournies via ce pseudo).
Le modèle ci-dessus a l'avantage de ne pas nécessiter de consensus mais peut être facilement adapté pour impliquer un consensus.
Question: découper une BC en modules la rend t-elle plus modulaire ?
(note: plus de modularité doit entrainer plus de ré-utilisabilité)
Vue: ensemble d'informations (dans une BC/BD ou un document) qui peut être spécifiée par une requête conceptuelle, typiquement une expression de chemin. Ainsi, la mise à jour d'un objet dans une vue est simplement l'ajout ou la suppression de relations à cet objet et a les même effets que sa mise à jour dans n'importe quelle autre vue montrant cet objet.
Module autonome [self-contained module]: ensemble d'informations dont les dépendances avec des informations externes sont rendues explicites dans le module via des commandes d'inclusion de module.
Module contextualisé: ensemble d'informations qui comprend - ou à qui est associé - une représentation de son contexte (source, hypothèses, restrictions, buts, ...). Ainsi, une phrase contextualisée est aussi un module contextualisée.
Module conteneur: module stocké dans un conteneur d'informations tel
un fichier ou un serveur de BCs. Une BC entière est un module conteneur et
peut être composée de sous-modules qui sont des modules conteneurs.
L'utilisation de "modules conteneurs qui ne sont pas aussi des vues sur une plus
grande BC" rend difficile pour les gens
1) de savoir quel fichier réutiliser, et
2) d'organiser les objets des différents BCs dans un réseau
sémantique bien organisé.
Ainsi, les modules conteneur conduisent à des redondances implicites et
des incohérences entre ces modules, et donc aux problèmes
répertoriés dans la page précédente.
De plus, pour le partage des connaissances, les approches basées sur les
modules conteneurs, la gestion des versions doit aussi être basés sur
des conteneurs (et donc des fichiers).
Cela conduit à divers problèmes qui ne peuvent avoir de solution
optimale en dehors d'une application particulière.
Une "BC construite coopérativement via une intégration sans perte"
n'a pas de tels problèmes. Par exemple, comment gérer la mise à
jour des identificateurs travers différentes BCs, comment répartir
les connaissances entre modules (i.e., combien et quels types de connaissances
chaque module doit avoir) ?
Il est préférable d'avoir une seule BC partagée et permettre
l'utilisation de requêtes conceptuelle laissant les gens
- utiliser des filtres conceptuels pour ne voir que ce qu'ils veulent voir
lorsqu'ils parcourent la BC, ou
- générer dynamiquement des fichiers à base de modules en fonction
de leurs préférences ou de contraintes d'application.
Si des modules conteneurs sont utilisés à des fins de partage des
connaissances (i.e., pendant la phase de modélisation et non celle de
l'exploitation),
- un module conteneur doit être une "vue" sur l'ensemble de la BC; ainsi,
mettre à jour un module doit être équivalent à directement
mettre à jour l'ensemble de la BC,
- comme n'importe quels autres types de modules dans une BC, les modules conteneurs
doivent être contextualisés ou bien seulement comprendre des
phrases contextualisées
- il doit être possible de parcourir et interroger l'ensemble de la BC
comme si elle n'était pas distribuée en modules conteneurs.
Pour conclure, utiliser ou non des modules conteneurs est essentiellement un
choix d'implémentation ou un choix dépendant des contraintes d'une
application.
Une BC unique est plus modulaire qu'un ensemble de modules conteneurs s'ils
peuvent être générés à partir de la BC et non l'inverse.
Rendre une BC plus organisée - i.e., augmenter le nombre de relations directes
ou indirectes entre les objets de la BC - augmente sa modularité (et sa
précision).
Une BC bien organisée peut ne jamais devenir "trop grosse" pour le partage
des connaissances. En effet, le qualificatif "trop grosse" dépend de
préférences particulières et une BC peut être vue/parcourue
avec un filtrage dépendant de ces préférences.
Question: serait-il avantageux de stocker des objets logiciels dans une BC construite collaborativement ?
Tous les modèles de conception de logiciels, modèles architecturaux de logiciels et langages de programmation de haut niveau proposent des moyens pour
Cela rend le code plus générique ou modulaire.
La (programmation) logique a l'avantage de permettre de quantifier des objets. Dans la plupart des LRCs et en logique du premier ordre, tous les objets sauf les quantificateurs sont objets de première classe, mais les prédicats ne peuvent être quantifiés. En logique du second ordre, les prédicats du premier ordre peuvent être quantifiés et des quantificateurs peuvent être définis.
Idéalement, les programmes devraient être écrits directement en utilisant un LRC mais c'est clairement difficile. Lorsque les objets logiciels sont très petits ou bien relativement grands (i.e., des instructions ou bien des programmes), les organiser par des relations sémantiques est difficile, surtout lorsque les objets ne sont pas déclaratifs (c'est pourquoi les méthodologies de génie logiciel se concentrent sur le développement et la réutilisation d'objets logiciels génériques et relativement petits mais multi-instructions). Ce problème n'existe pas avec des représentations de connaissance: il est plus facile de relier des phrases indécomposables que les groupes de phrases.
Dans tous les cas, l'utilisation d'une BC construite collaborativement serait intéressante pour stocker une bibliothèque d'objets logiciels. Cela permettrait à des programmeurs d'organiser des objets logiciel (e.g., des structures de données, classes, instructions, règles, procédures, modules) par des relations sémantiques et de les relier à des objets de connaissances plus classiques (i.e., non liés aux logiciels). Cela permettrait alors ensuite à des utilisateurs d'écrire des requêtes conceptuelles pour générer et à assembler des modules logiciels.
Il peut sembler impossible d'utiliser des "modules-qui-soient-aussi-des-vues"
sur une grande échelle sans avoir un système centralisé.
Pourtant, il est possible de combiner
- la centralisation des informations (qui conserve un réseau unique
sémantique,
ce dont le partage des connaissances a besoin) avec
- l'approche basée sur le Web pour des actions distribuées.
A l'échelle du Web, cela impliquerait une BC virtuelle mondiale
composée de BCs réelles (qui seraient des modules-vues, comme
décrit précédemment) créées par des individus ou
des communautés,
sans système central de répartition/retransmission
d'informations/requêtes,
sans restrictions sur le contenu de chaque BC, et
sans que les serveurs de BCs individuels aient nécessairement à
s'inscrire à une super-communauté ou
à un réseau pair-à-pair (P2P).
Pour arriver à cela, il est nécessaire que le choix de la BC qu'un agent décide d'interroger ou de mettre à jour n'ait pas d'importance. Des ajouts, mises à jour ou requêtes d'objet effectués dans une BC doivent être retransmis toutes les autres BCs dont le domaine couvre cet objet. Plus précisément, pour satisfaire les spécifications ci-dessus, pour qu'un serveur de BCcc (BC construite coopérativement) soit un module-vue d'un ou plusieurs BCcc-GV (BCcc global virtuel), il faut que pour chaque terme T stocké dans sa BCcc, ce serveur
Ainsi, via des retransmissions entre serveurs, tous les objets utilisant T peuvent être ajoutés ou trouvés dans chaque nexus pour T. Cette exigence est une adaptation et un raffinement de la 4ème règle de l'approche "Web de données" du W3C: "il faut lier le plus possible de choses d'un module à des choses d'autres modules". En effet, pour obtenir un BCcc-GV, les modules doivent être gérées via des serveurs BCcc et il doit y avoir au moins un nexus pour chaque terme. Une conséquence est que lorsque les domaines de deux nexus se chevauchent, ils partagent les mêmes connaissances communes et il n'y a ni contradictions ni "redondances implicites" entre ces deux nexus. En d'autres termes, chaque BCcc est bien une vue sur une partie du BCcc-GV.
Dans la société MONDECA en 2012.
MONDECA: Editeur logiciel, expert dans les technologies du Web Sémantique.
Fondée en 2000, Mondeca est une structure de taille humaine qui investit largement dans l'innovation. Ce travail se traduit par l'évolution permanente de notre offre produit, "Smart Content Factory", diffusée en France comme à l'international, en relation avec notre réseau de partenaires techniques et intégrateurs. Nos solutions d'organisation des informations, connaissances et contenus hétérogènes adressent les besoins de valorisation des contenus et du capital informationnel des organisations (annotation sémantique des contenus, optimisation des moteurs de recherche, publication de données ouvertes et liées, raisonnement). Nos clients sont des grands comptes dans les domaines de l'édition, de l'industrie, du tourisme, des sciences de la vie ou des organismes publics. Mondeca s'appuie sur les technologies J2EE, les standards du Web sémantique et une expertise de haut niveau. Nous nous impliquons dans les travaux de normalisation du W3C et participons activement à plusieurs projets collaboratifs nationaux et européens. La R&D est une composante essentielle de notre activité et contribue à faire de Mondeca un acteur incontournable. L'essor des technologies Web Sémantique, notamment dans le monde de l'Open Data, nécessite pour Mondeca un renforcement de ses équipes.
Dans la société TGE ADONIS en octobre 2012.
Dans le cadre de la mise en œuvre de DARIAH (http://dariah.eu/), le TGE ADONIS (http://www.tge-adonis.fr/) recrute pour une mission de 3 ou 4 mois, un/e ingénieur/e de recherche CNRS contractuel, chef de projet ou expert en développement et déploiement d'applications.
Mission : L'objectif principal de la mission consiste à étudier les possibilités d'interopérabilité documentaires et de requêtage entre les deux plateformes ISIDORE (http://www.rechercheisidore.fr/ ) et Narcis (http://www.narcis.nl/ ) dans le but de définir une ou plusieurs façon de requêter de façon simultané et croisé les deux plateformes (interconnexion).
Dans un premier temps, il s'agira de produire une description fonctionnelle des deux systèmes, de leurs chaînes de traitement respectives et une description des API disponibles dans chacun des deux systèmes.
Dans un deuxième temps, il s'agira de produire des propositions techniques et
organisationnelles, nécessaires à une interconnexion (requêtes, navigation,
interaction entre les métadonnées).
Dans un troisième temps, il s'agira de développer différents prototypes pour
illustrer les différentes solutions d'interconnexion et/ou les problèmes
soulevés par ce projet.
Compétences :
- Bonnes connaissances sur les concepts du Linked Data et du Web sémantique (RDF, RDFa, SPARQL);
- Bonnes connaissances en ingénierie logicielle et maitrise des concepts d'API ;
- Capacités à prototyper (programmation java et/ou Python, et/ou Javascript, et/ou Perl, et/ou Php) pour réaliser des tests et démonstrateurs ;
- Capacités à analyser des spécifications détaillées et à réaliser des analyses fonctionnelles (maitrise d'UML souhaitée) ;
- Connaissances en Information scientifique et technique : Dublin Core, OAI-PMH, microformats, etc.
- Maitrise de l'anglais oral et écrit. Le travail nécessite la participation à des réunions de travail en anglais et la rédaction de documents en anglais.
Lieu de travail : TGE Adonis, Paris 5ème. La mission nécessitera des déplacements et des brefs séjours (8 à 10 jours) à La Haye (NL) et à Lyon.
Comprendre (ou aider à comprendre) = trouver l'information manquante dans
un(e étape de) raisonnement et donc dans une implication. E.g.:
Étape 0 (information initialement connue): A=>B, B=>C
...
Étape x: A=>B, B'=>Z //B=>B' laissé implicite car supposé connu (déjà dit, ...)
Étape z: A=>Z //si le passage de x à y n'est pas compris par une personne,
// celle-ci doit chercher/demander comment on passe de B à B'
...
Dernière étape (information à montrer/comprendre/...): A=>Z, B=>Y, C=>X, ...
Exemples de sujets:
Exemples de ressources sur SPARQL:
- Tutoriel pointant sur les exemples de serveurs suivants
- serveur générique (il faut lui indiquer l'URL d'une BC):
Redland Rasqal
- serveurs dédiés à certaines BCs:
DbPedia,
Health data.
- ressources pour SPARQL à l'INRIA:
- tutoriel avec l'outil Corese
- Functionalities added by Corese
- introduction générale
- SPARQL 1.1 Query
- SPARQL Update
Exemples de ressources sur RDFa et les microformats:
(pour stocker des connaissances très simples dans des tags HTML):
- Wikipedia (cf. liens ci-dessus)
- le W3C (e.g., cf. liens ci-dessous pour RDFa)
- RDFa: syntaxe, "primer"
- tutoriaux (e.g., celui de Roger Costello sur les microformats)
- le micro-format de Google: Schema.org
Exemples de ressources sur Protégé
(l'éditeur de représentation de connaissances le plus utilisé actuellement):
- wiki sur Protégé
- tutoriels (lisez celui-ci d'abord)
- téléchargements (essayez celui-ci d'abord); pour faciliter le TP, tous
les étudiants de ce cours téléchargeront une version de Protégé.
Exemples de ressources sur Freebase:
- son rachat et utilisation par Google:
1,
2,
3,
4
- wiki pour les developpeurs de Freebase (utilisez MQL, ...)
- Freebase versus DBpedia
- Notes techniques: 1
Exemples de ressources sur Yago:
- Cf. lien ci-dessus, télécharger Yago avec le "Jena TDB store" et
effectuer des requêtes locales via SPARQL (montrez les sorties dans différents formats)
Sujet sur les ontologies de langages: comparer OWL 2, SKOS,
la Frame-ontology de Ontolingua, OKBC et CL (lire/parcourir le document ISO).
Compte-tenu de ce sujet, l'exposé devra bien-sûr prendre en
compte les
pages 7, 10, 11, 14, 15, 22 et 23 du cours.
Cet
exposé pourra utiliser des
tables de comparaisons (comme dans
cet exemple et
celui ci)
pour comparer ces ontologies de langages.
Les autres exposés pourront bien-sûr aussi utiliser de telles tables.